今 Q もお疲れさまでした!10X の @metalunk です.
3ヶ月前に 10X の検索を 10x したい というブログを書きました.その記事にあるとおり,1-3月で検索インフラの改善を実施し,検索速度 10x, インフラコスト 80% 削減という成果をあげました.そして,直近の3ヶ月では検索精度の改善に取り組みました.この記事では今 Q にリリースした機能と,それぞれの効果を説明します.
長い記事になったので飛ばし飛ばし読んでください.
どんな Q だったか
- 検索インフラの大きな問題が前 Q で解決し,精度改善に取り組み始めた
- 精度改善の準備をし,新しい検索エンジニアが入ってきたときに,すぐに精度改善に取り組める状態になった
- 作戦リストを作り,インパクトの大きいものから順番に取り組むことで検索精度が着実に改善した
KPI の変化
検索の KPI は Zero match rate と Conversion rate の二つです.
Zero match rate
Zero match rate は,全検索のうち結果が0件であった検索の割合です.ゼロマッチを減らすには検索精度を改善することと,品揃えを拡充すること(セレクション)の両輪が重要です.
3ヶ月前と比較し,18.8% のゼロマッチを削減することができました!👏👏👏

Conversion rate
Conversion rate は全検索のうちカート追加が発生した検索の割合です.ネットスーパーの特性上,商品詳細ページに行かずに一覧ページから直接カート追加することが多いため,CTR (Click through rate) ではなくカート追加の Conversion rate を採用しています.
3ヶ月前と比較し 2.3% 改善しました.Zero match rate を下げる施策を優先したため,大幅な改善はできませんでした.
リリースした機能
ではここから,この3ヶ月でリリースした機能と,それぞれの評価を説明します
検索キーワードサジェスト
お客さまが検索キーワードを入力中に,キーワード候補をサジェストする機能を作りました!👏
うわあ!ライフのネットスーパーアプリで検索がしやすくなってる!
— Ryusuke Chiba (@metalunk) 2022年6月8日
文字を入れると検索キーワード候補がサジェストされるし,検索結果画面にもカテゴリの絞り込みフィルタがある!
便利だなあ!
(やるべきことを順番に改善しております) pic.twitter.com/ojsEe0zCd3
システム概要

キーワード候補はイベントログから生成しています.検索経由のカート追加ログを集計し,キーワードごとのカート追加数を数え,そのカート追加数を Weight として Elasticsearch の index を作ります.検索時には入力中のテキストにヒットしたものを Weight 順(カート追加が多い順)に表示します.
この方法の良い点は,より利用されているキーワードが上位に表示されることと,カート追加がないキーワード(ゼロマッチなキーワードだったり,検索精度が悪いキーワードだったり)はサジェストされないことです. これによって,お客さまがよりよいキーワードで検索するサポートをすることができ,ゼロマッチを削減することになります.
また,文字種(漢字,ひらがな,カタカナ,ローマ字)が異なってもヒットさせる工夫や,先頭からマッチさせるだけでなく wildcard でマッチさせる工夫をしております.
さらに,毎日 index を作り直しているため,データの変化に自動的に対応できます.
index はパートナーごとにそれぞれのイベントログから生成しているため,それぞれの特徴が生かされたものとなります.例えば,ライフで「ライフ」と入力すると彼らのプライベートブランドである「ライフプレミアム」や「スマイルライフ」がサジェストされます.
一方,イベントログから生成するデメリットに,十分なデータがないとキーワード候補が生成できない問題(コールドスタート問題)があります.まだ利用数が少ないパートナーでも利用できるようにするためにマスターデータからキーワード候補を生成するなど,作戦はいくつか考えてあり,将来実装されます.
評価
この機能により,12.7% のゼロマッチ検索を削減し,1.1% CTR を向上しました!👏
カテゴリフィルタ
検索結果をかんたんにカテゴリで絞り込むことができるようにしました!👏
例えばマグロのキャットフードを探しているときに「マグロ」と検索するとマグロのお刺身,キャットフード,ドッグフードがヒットします.そんなときはキャットフードの絞り込みボタンをワンタップするだけで,キャットフードに絞り込んだマグロの商品を探すことができます.

とてもシンプルですが,かなり便利な機能です.お客さまのサポートをすることで,まだ精度が高くない Stailer の検索を使いやすくする機能だと思います.
並び順の改善
「関連度順」の並び順を改善しました!👏
一目瞭然なので見てください.

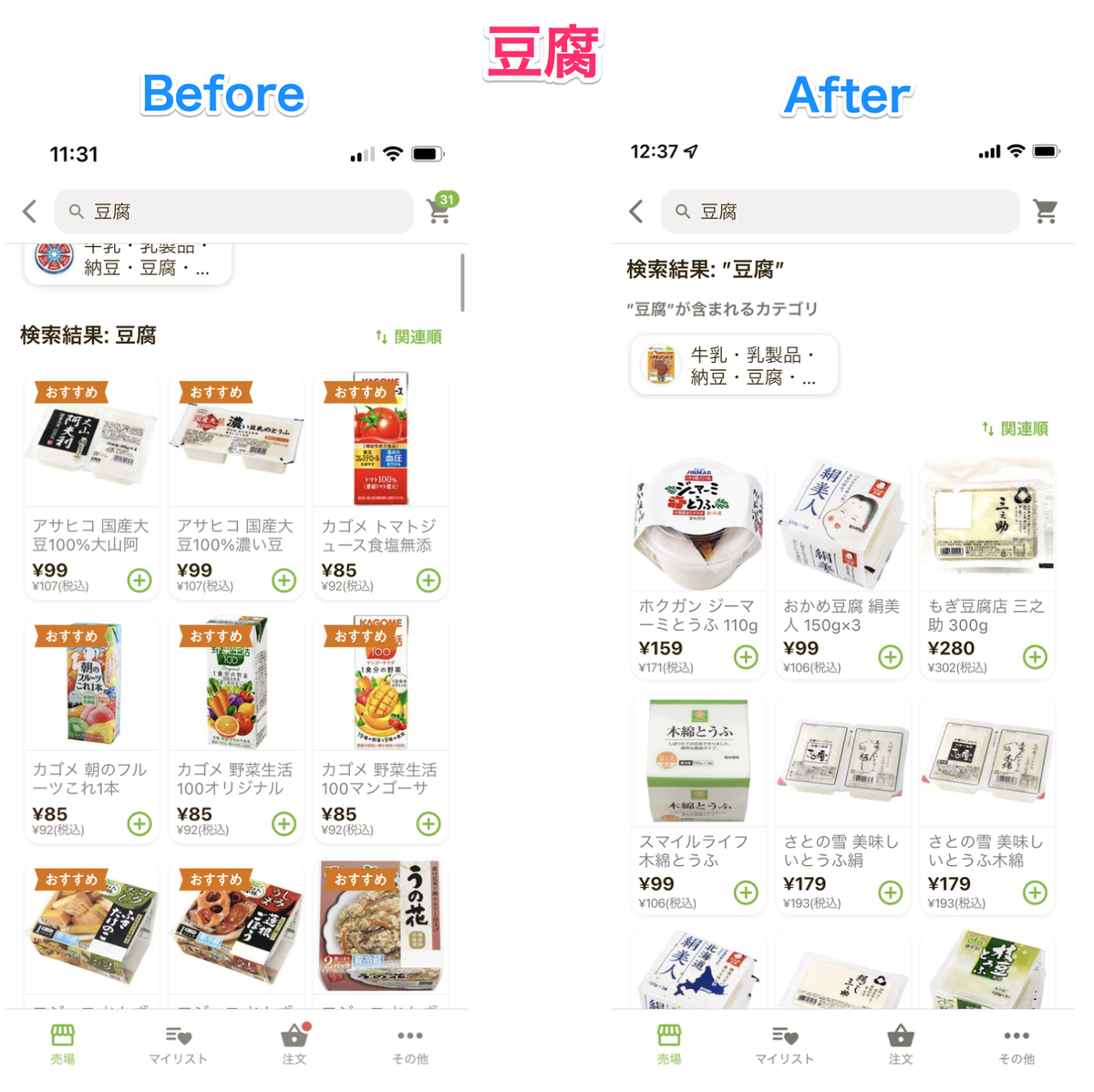
実は,並び順が悪い問題は一部の商品だけで発生していました.以前から問題があることはわかっていましたが,優先度が高い問題が他にあったせいで,原因究明すらできていない状態でした.
問題の原因は Elasticsearch に渡されるソートの指定が間違っていたことでした.一見単純に思えますが問題の根は深いです.この問題の根本原因は,Elasticsearch に投げるクエリを生成する実装が複雑になっており,正しい実装をするのが難しかったことです.対策として部分的にリファクタリングを行うことにしました.
さらに,この問題はバグが原因であり,リリースしたときに気づけるべきだったという反省があります.現在は Metrics をモニタリングしており,同様の事象が発生したら気づける状態になっております.
評価
CTR を 5.8% 向上させました👏
bigram
bigram を導入し,これまでヒットしなかった商品がヒットするようになりました!👏
これも Before & After をご覧ください.
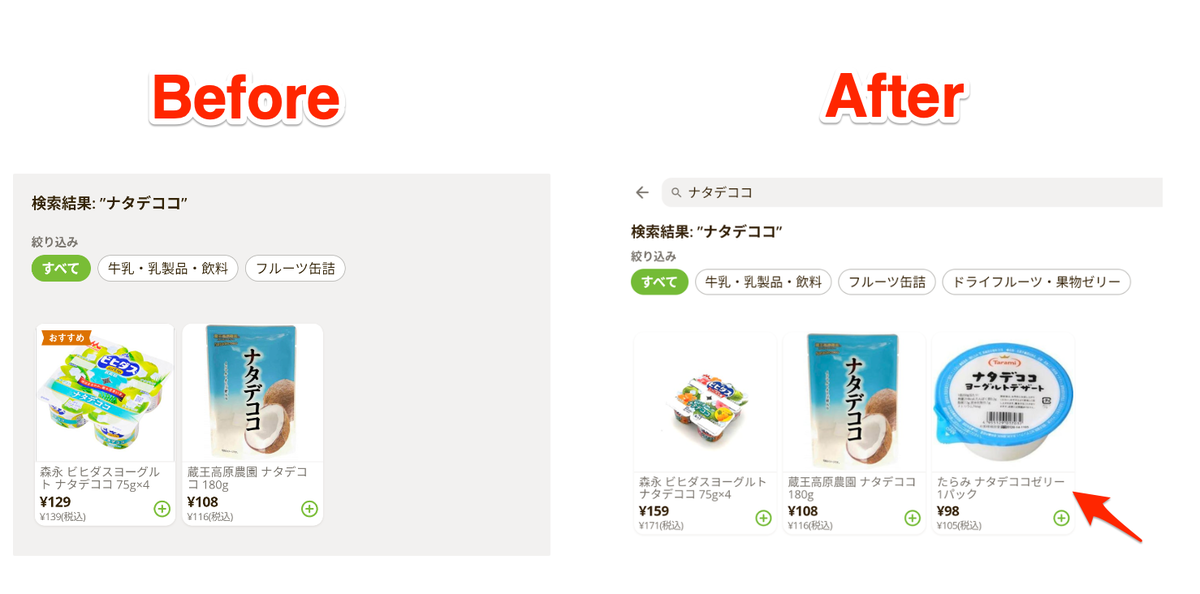
解説
「たらみ ナタデココゼリー」が「ナタデココ」でヒットしなかったのは,ナタデココが未知語だったからです.
検索に詳しくない人向けにかんたんに解説します.まず,検索を提供するには本と同じように索引を作る必要があります.索引には単語を収録したいので,ドキュメントを単語単位で区切る必要があります.しかし,日本語を単語に区切るのは難しいのです.英語であれば単語間はスペースで区切っているため,分割するのは簡単ですが,日本語の場合そうはいきません.(日本語 も この よう に スペース 区切り で 書い たら いい の に ね)日本語を単語分割する方法は自然言語処理の分野で研究されており,我々はその成果を利用しているわけです.
Stailer では Kuromoji という形態素解析器を利用して単語分割しており,それは辞書を利用します.その辞書に「ナタデココ」が入っていないため(つまり未知語),Kuromoji は「ナタデココ」を単語として認識できず,結果的に,「ナタデココ」で検索してもヒットしないわけです.
実際に Elasticsearch の Analyze API を叩いてみると「ナタデココゼリー」が一つの単語 (token) として分割されています.(katakana_index_analyzer の定義は書いていませんが,kuromoji_tokenizer を tokenizer に指定してあります)
Request
GET /stocks/_analyze
{
"analyzer" : "katakana_index_analyzer",
"text" : "たらみ ナタデココゼリー"
}
Response
{
"tokens" : [
{
"token" : "タラミ",
"start_offset" : 0,
"end_offset" : 3,
"type" : "word",
"position" : 0
},
{
"token" : "ナタデココゼリー",
"start_offset" : 4,
"end_offset" : 12,
"type" : "word",
"position" : 1
}
]
}
この問題を解決するために bigram を導入しました.bigram は2文字区切りで単語 (token) 分割します.「たらみ ナタデココゼリー」はこのようになります.(bigram_index_analyzer の定義は書いてありませんが,ngram の min_gram, max_gram ともに 2 の tokenizer を指定してあります)
Request
GET /stocks/_analyze
{
"analyzer" : "bigram_index_analyzer",
"text" : "たらみ ナタデココゼリー"
}
Response
{
"tokens" : [
{
"token" : "タラ",
"start_offset" : 0,
"end_offset" : 2,
"type" : "word",
"position" : 0
},
{
"token" : "ラミ",
"start_offset" : 1,
"end_offset" : 3,
"type" : "word",
"position" : 1
},
{
"token" : "ナタ",
"start_offset" : 4,
"end_offset" : 6,
"type" : "word",
"position" : 2
},
{
"token" : "タデ",
"start_offset" : 5,
"end_offset" : 7,
"type" : "word",
"position" : 3
},
{
"token" : "デコ",
"start_offset" : 6,
"end_offset" : 8,
"type" : "word",
"position" : 4
},
{
"token" : "ココ",
"start_offset" : 7,
"end_offset" : 9,
"type" : "word",
"position" : 5
},
{
"token" : "コゼ",
"start_offset" : 8,
"end_offset" : 10,
"type" : "word",
"position" : 6
},
{
"token" : "ゼリ",
"start_offset" : 9,
"end_offset" : 12,
"type" : "word",
"position" : 7
}
]
}
検索クエリの「ナタデココ」も同じように Analyzer によって token 分割され,検索されます.ヒットに仕方はクエリによりますが,今回使っている match_phrase の場合は「ナタ」「タデ」「デコ」「ココ」のすべての token がその順番に含まれるドキュメントにヒットします.要は,grep のような部分一致で検索できるようになりました,ということです.ちなみに,match クエリだと語順が合っていなくてもヒットしてしまうため,match_phrase クエリが bigram での検索には適していると判断しました.
評価
Recall が向上しました.
特に,数字を含むクエリ,アルファベットを含むクエリの Result count(検索に引っかかった件数)が向上しました.

シノニム辞書を Search time に展開
シノニム辞書を Search time に展開するように変えたことにより,改善サイクルを高速化しました!👏
解説
シノニムとは,同義語のことです.シノニム辞書に「ポテチ,ポテトチップス」を追加しておくと「ポテチ」で検索したときに「ポテトチップス」をヒットさせることができるようになります.
シノニム辞書は Index time, Search time, またはその両方で展開する選択肢があり,Stailer では Index time, Search time の両方で展開する仕組みになっていました.
Index time に展開する問題点は,シノニム辞書に変更があったときに Reindex か Update by query のどちらかをする必要があることです.弊社の Elasticsearch は Reindex に2時間ほどかかる状態であり,作業がめんどうなので,積極的にシノニム辞書の更新をしたくない状態でした.(もっと気軽に Reindex をできるようにするために Reindex を速くする改善策も将来的にやりたいです)
一方,Search time にシノニム展開をする場合は,Index の Reload をするだけでシノニム辞書の変更を反映させることができます.特に,Elastic Cloud を利用している場合は,console 画面から辞書の plugin を変更するとそれぞれの node に辞書が配られ,Reload まで自動的にされるはずです.変更にかかる時間は5分ほどです.
Search time にシノニム展開をすると,リクエストのたびにシノニム辞書を引くことになるため時間はかかりますが,これは問題にならないレベルで,その他の多くのメリットが上回るため,Search time に展開するよう決定しました.
詳しくは Elastic 社のブログ “違い”を生む“同じ”:Elasticsearchのパワーを増大させる“同義語” の「インデックス時 vs 検索時」をご覧ください.
さらに,Search time と Index time どちらでもシノニム展開をすると,辞書の内容によっては展開しすぎてしまい,一見関連しない商品がヒットする問題がありました.Search time だけでシノニム展開することで,この問題も解決しました.
イベントログからシノニムルールの生成
お客さまの行動ログからシノニム辞書を作りました! 👏
解説
アイディアはこうです.あるお客さまが「ポテチ」で検索したときに検索結果が0件だった.次にそのお客さまは「じゃあキーワードを変えて,ポテトチップスで検索してみよう」と考え「ポテトチップス」で検索したら商品が出てきて,カート追加した.この行動は「ポテチ」と「ポテトチップス」が同義語であることを表現しているから,同じようなログを集めたら同義語辞書を拡充できるのでは,というわけです.
ログから生成されたシノニム候補はお客さまが実際に Stailer の上でクエリを書き換えた行動から生成されたもので,価値の高いものがたくさん含まれていました.
しかし,シノニムに適していないものも含まれていました.例えば「超熟」と「超塾」のようなタイポはシノニムではなく,キーワードサジェストで救われてほしいし,「無塩バター」と「バター」は部分集合の関係であるから「バター=>無塩バター」なら OK ですが「無塩バター=>バター」は間違いでしょう.
この判断を自動化するのは難しいため,まずはある程度絞り込んだシノニム候補370件を一つずつ見て手動で選別することにしました.(かなりくたびれました)
将来的に自動化したいと言いたいところですが,シノニム辞書はずっとこのペースで追加され続けるものではなく,Stailer で使われる検索キーワードのうち大部分がサポートされたら,それ以降はそれほど更新は多くないと思っています.またそのときがきたらゴリラのようなパワーでやっつけると思います.
改善の背景
これらの改善の背景には,改善をするための準備がありますので,それについても説明します.
KPI Dashboard, クエリグループ Dashboard の準備
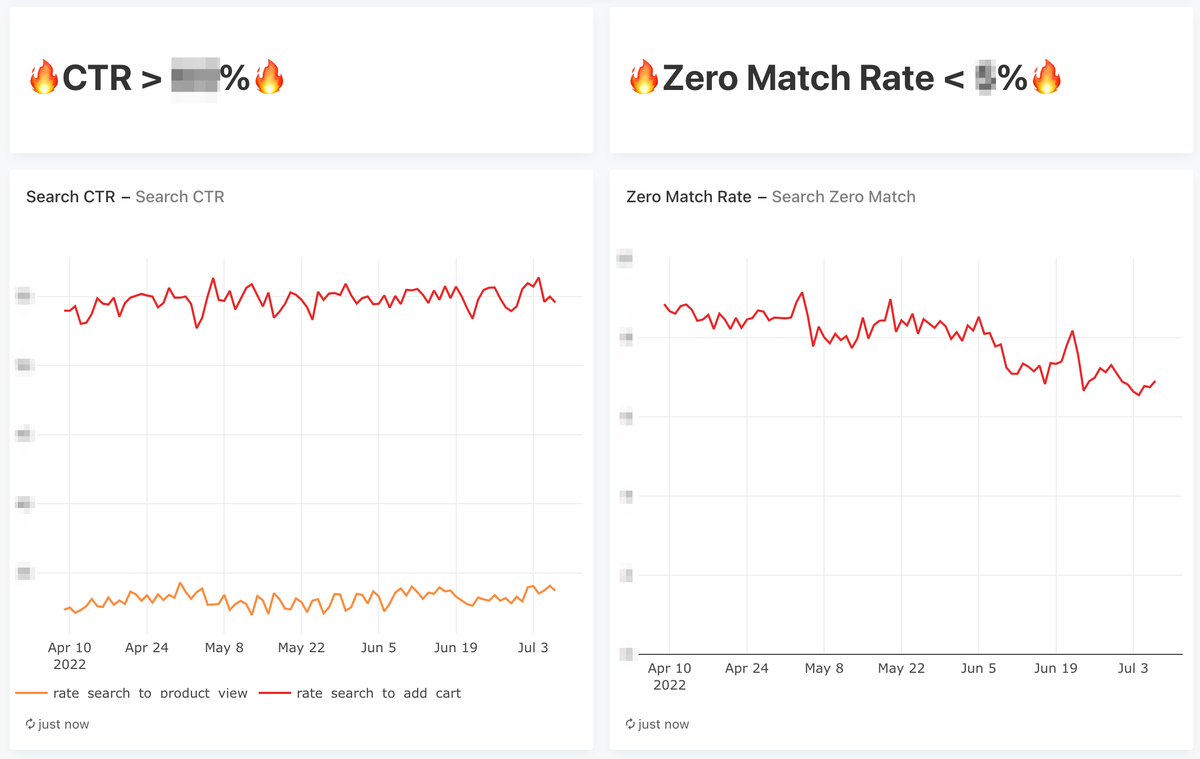
検索精度を改善する前に,まずは Metrics をモニタリングするためのダッシュボードが必要であると判断し,二つのダッシュボードを作りました.
一つ目は KPI Dashboard です.KPI は Conversion rate と Zero match rate です.今 Q にリリースしたものはほとんど全て,やったらいいに決まっている機能だったため,AB テストは実施しませんでした.しかし,それぞれの施策の評価をしないとあとで振り返れなかったり,次にどの施策を実施するべきか判断できないといった問題が生じます.そのために KPI Dashboard は必須でした.
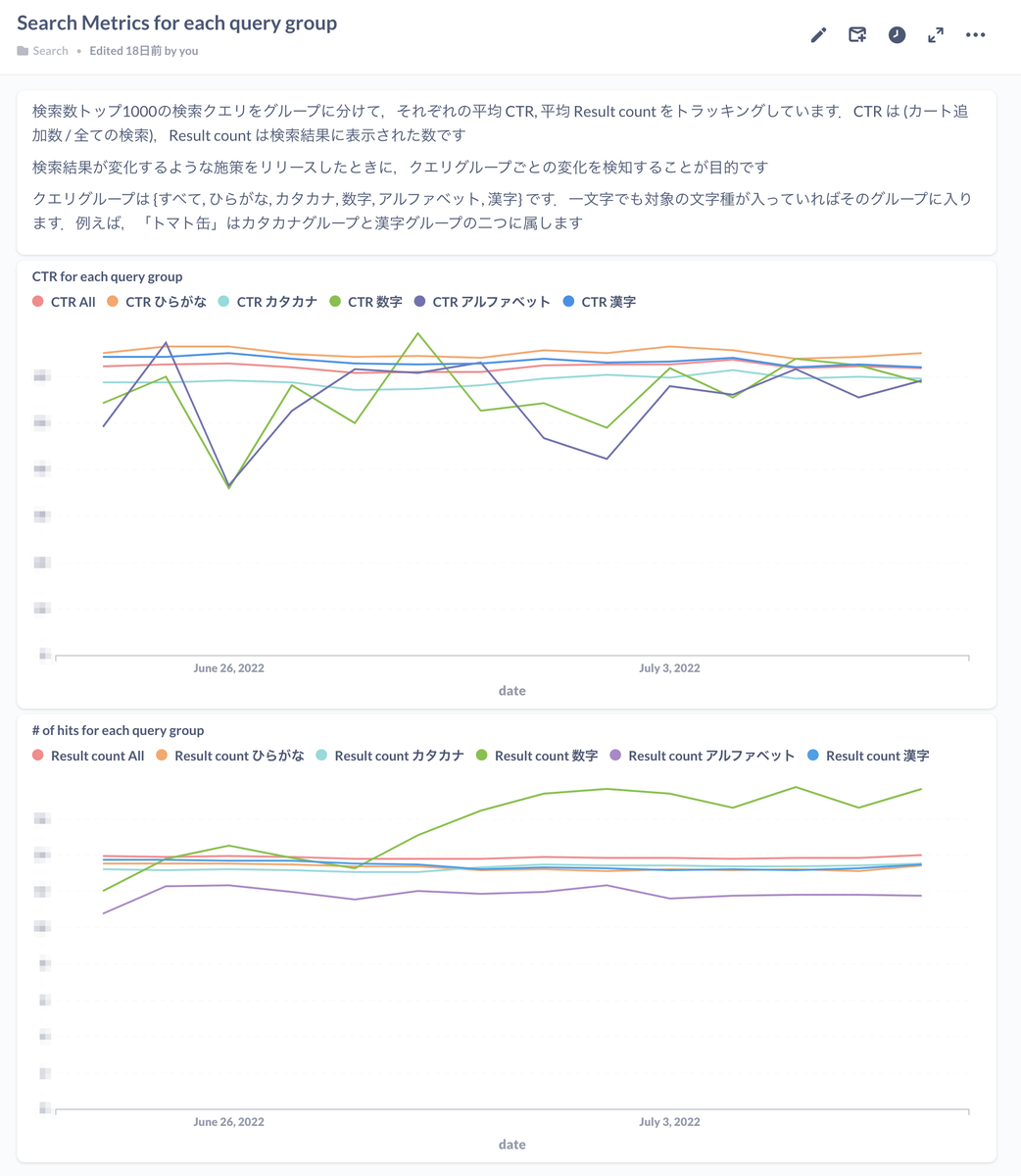
二つ目のダッシュボードはクエリグループごとの各種 Metrics です.クエリグループとは,人気検索キーワードを文字種ごと(漢字,ひらがな,カタカナ,アルファベット,数字)にわけたものです.クエリグループに分けている意図は,Analyzer の変更などによって,ある特定のクエリグループだけの Metrics に変化があることが想像でき(例えば,bigram を導入したら数字のクエリだけ CTR が上がるとか),それをトラッキングしたかい,ということです.
検索結果を local で試せる状態にした
Analyzer を変更したり,クエリを変更したときに,検索結果にどんな変化があるのか知りたいことはありませんか?本番にリリースする前にまずは local で,変化の大きい検索キーワードとその結果を一覧できる状態にしました.
比較表の一部はこんな感じで,検索キーワード「和菓子」に対する旧結果と新結果が並んでいます.similarity が低い順に見れば,変化の大きいものから見ることになり,効率的にチェックできます.この例では,右の新結果の方が和菓子っぽいものが並んでおり,いい結果に見えます.

検索結果の保存,比較には Ubie が OSS として提供している esqa を利用しました.
このおかげでリリースせずに検索結果の変化を知れるため,改善サイクルが高速化しました.
ただし,ある程度精度が高い状態になるとこのような比較は難しく,AB テストでしか比較できない状況になると思います.しかし,Stailer の検索は明らかに改善できる検索結果がまだまだあるため,このような方法が使えます.
おわりに
私が入社してからのこの半年間で,検索のインフラ改善,精度改善を実施し,多くの問題が解決されました.しかし,検索の専任は(検索の専門家ではない)自分一人であり,チームとして働けている状態ではありません.
次の Q ではチームとして検索改善を進めるための改善を進めようと考えています.例えばリファクタリングや,Reindex の高速化,AB テストをかんたんにできる環境の構築などです.そういうわけで,これを読んでいる検索のスペシャリストのあなたが入ってくる頃には大活躍できる状態になっているはずです.ご応募お待ちしております!
さらに,検索だけでなく推薦にも取り組もうとしております.これまでは,まずはお客さまが能動的に探せるようにする,ということで検索に注力しておりましたが,そろそろ受動的に商品を推薦される体験を提供したいです.はじめは小さくルールベースからですが,将来的には機械学習を利用した推薦を提供するはずです.これを読んでいる推薦のスペシャリストのあなた,私が MLOps エンジニアとしてあなたのモデルを動かす環境を準備してお待ちしております!
まだ応募を考えていない方はカジュアル面談させてください.この記事について話したい,Stailer の検索の話が聞きたい,10X について聞きたいという方は気軽にこちらからカジュアル面談の申し込みをお願いします!