 10Xでコーポレートエンジニアをやっているハリールです。
10Xでコーポレートエンジニアをやっているハリールです。
このブログでは、社内サービスデスク・ヘルプデスクの運用において、問い合わせの受け付けから始まるデータの流れ、そのデータの蓄積方法、そしてそのデータを活用して改善サイクルをどのように回していくかについて、試行錯誤を重ねてきた経験、LLM活用方法、構成、実用的なTipsなどをまとめています。
前提条件
以下のサービスを使って構成しています。 各SaaSの基本的な利用・操作について記載はないためある程度理解している前提での記述となっています。
- Slack
- Jira Service Management
- Zapier
- OpenAI
- Looker Studio
全体構成
全体構成としては
- 問い合わせのI/Fは日常最も利用するチャットツール(Slack)を利用し、ツールのスイッチングコストをかけない。
- チャットツールで投げた問い合わせはチケット管理ツール(Jira Service Management)に双方向同期し、情報の欠落・重複データを防止。
- チケット管理ツールにデータが投入されると内容を元に要約・タグ・分類などを自動生成することで属人的な作業を減らし、精度の高いデータを蓄積。
- 蓄積されたデータをBIツール(Looker Studio)に連携・可視化。定期的な振り返りを実施し改善サイクルを回していく。
といった流れとなります。
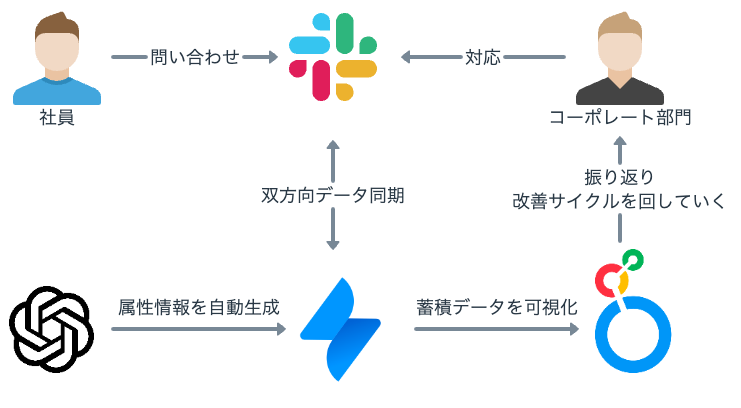
SlackとJira Service Managementとの連携
基本的な設定は以下に公式ドキュメントがあります。 www.atlassian.com 上記設定によってSlackの投稿をJira Service Managementに蓄積する構成が実現できます。 それを踏まえた上でのTipsをまとめていきます。
Tips1. プロジェクトタイプ
Jira Service Managementで利用できるプロジェクトは以前までは企業管理型のみでしたが、現在はチーム管理型も作成できるようになっています。 現在10Xではチーム管理型で運用していますが特に大きな課題はありません。それぞれのプロジェクトの特性や相違点については以下を参照ください。 support.atlassian.com
Tips2. Slackチャンネル情報の登録
Slackのメッセージから同期されているJiraチケットへ遷移したい場合、SlackにJiraチケットへのリンクがあるので問題ないのですが、その逆にJiraチケットからSlackメッセージに遷移したい場合には以下の設定を行うことで実現できます。
設定方法はチケットの属性に requesterChannelLink といった名前で文字列型のカスタムフィールドを設定するだけです。
これでJira Service Managementが自動でSlack投稿へのリンクを挿入してくれます。


requesterChannelLink にはリクエストを受け付けた発言へのリンクが、slackCreationChannel にはチャンネル名が自動で設定されます。
なお、他にどのような属性が指定可能かについては以前まではHalpやAtlassianのドキュメントに記載がありましたが、現在記述がなくなっており、今後この機能がなくなったり、非推奨となる可能性がありますのでその点ご了承ください。
Tips3. Emoji ショートカットAutomation
Jira Service Managementのチャットはその前身であるHalp時代から絵文字リアクションによる操作が特徴でした。 Slack上でチケットの投稿に対して、 👀 をリアクションして担当になったり、完了を意味するリアクションでチケットを完了させることができます。
なお、現在もその設定はありますが、2024年6月4日までにJira Automationに移行させる必要がありますのでご注意ください。 移行の手間はあるものの、利用可能なアクションの範囲が拡大し、様々な操作をリアクションベースのトリガーで実行できるようになったことは、歓迎できる点だと思います。
詳細は以下を参照ください。
チケット属性をLLMで自動生成
チケットが作成されると以下の情報を自動生成しています。
- 要約/説明
- タグ
- 分類
生成はJira(Automation)からZapierを経由してOpenAIを呼び出しています。それぞれの詳細を記します。

AutomationからZapierコール
まずは、対象プロジェクトに課題が作成されるとZapierにWebリクエスト(WebHook)を送信するAutomationを用意します。
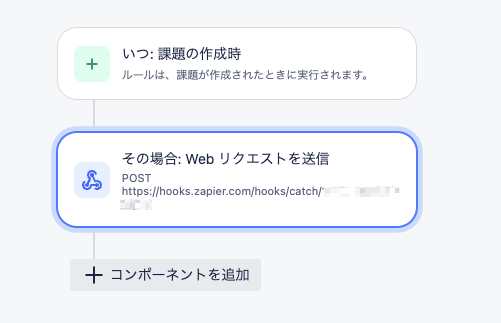
Webリクエストの本文はカスタムデータとし、後続処理で必要なデータを設定します。更新時のチケットを特定するためのkeyと、生成元となるsummaryを設定しています。
なお、reporter(報告者)はZapierから再度Jiraチケット更新する際の必須項目となるため設定しています。
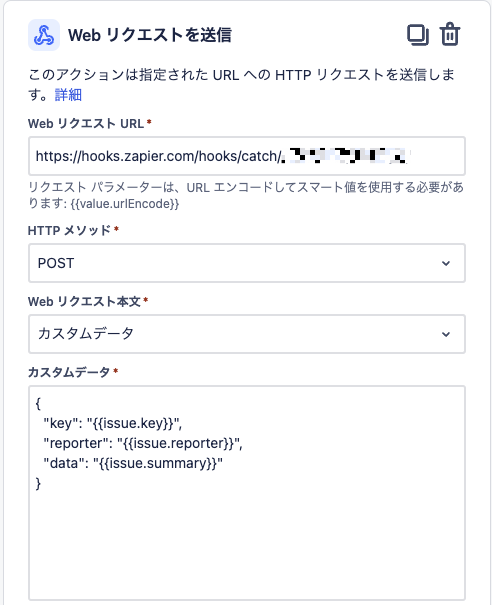
これで自動生成の準備ができました。
余談. データに改行が含まれる場合の注意点
上記のカスタムデータは問題ありませんが、例えばカスタムデータで渡すデータに改行が含まれる場合、上記の記載方法では正常にZapierを呼び出すことができません。さらにいうとJira Automation上の検証は成功するがZapierは呼び出されないためなかなか原因に気付きにくいです。 その場合の対応については以下を参照ください。
要約/説明
続いてユーザーからの問い合わせ内容を元に、要約と説明を生成します。なお、SlackとJira Service Managementの連携では問い合わせの元の文章は自動的に最初のコメントに記録されるため、今回のように加工したとしても元の情報が失われることはありません。 以前までは長文の場合のみコメントに記録されていましたが、いつからか現在の仕様になりました。このほうが便利ですね。 Automationから呼び出されるZapで ChatGPT ActionかOpenAI Actionを選択しますが、どちらを使っても結果に大きな差はないためどちらでもOKです。今回の例ではChatGPT Actionを使います。
まず要約の生成では以下のプロンプトを指定します。10文字程度と指定していますが、稀に改行が含まれてしまいJiraに設定する際にエラーになることがあるため、改行を含めないような指示も加えています。
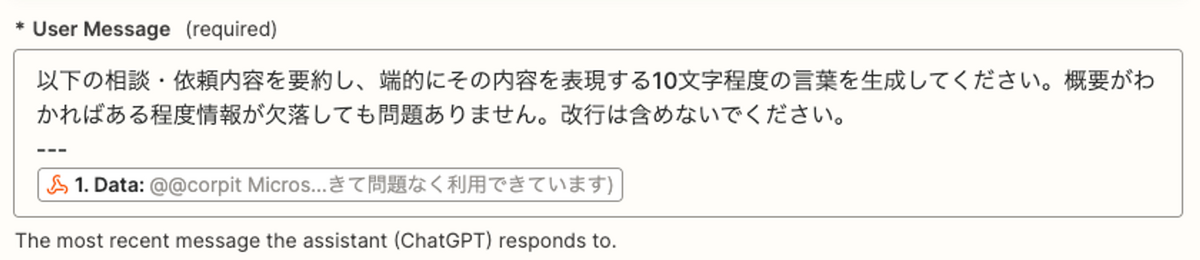
その他のパラメタ(ModelやMemoryKeyなど)はそれぞれお好みで指定してください。
続いて説明を生成します。説明はJiraチケットの複数行フィールドのため改行は気にせずかつ文字数の制約なども指示する必要はありません。かなりシンプルな指示なためお好みでカスタマイズしてください。

タグ
続いて問い合わせ内容からタグを生成します。以下のような指示で生成しています。カンマ区切りとしているのは、後続のJiraへの反映時にそのまま投入できるからです。
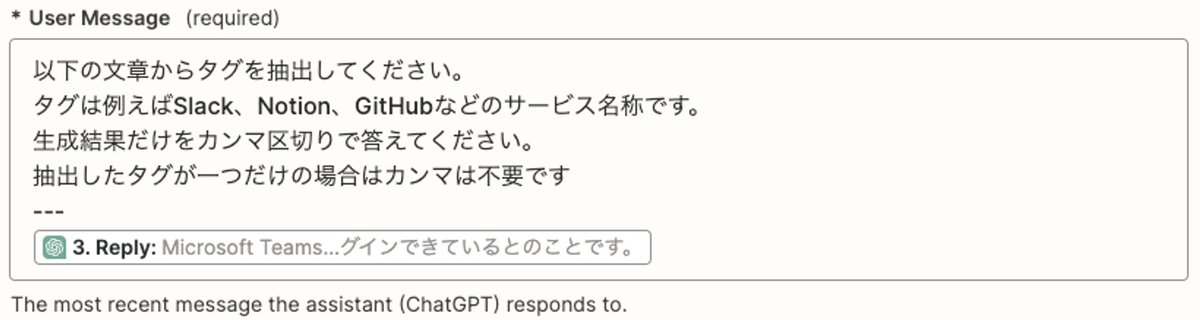
なお、生成されるタグについては、文章によっては想定外のタグ(個人名やメンションなど)が含まれることもあるため、”ある程度雑に生成されたものをチームのデイリーなどで共有しながら手直しする”前提で運用しています。
それでもすべてを手動で付与していくよりははるかに効率的になったと実感しています。
余談. その他タグを使わない
LLMでタグを生成する際、分類できない場合に ”その他” を設定したくなりますが(というか最初はそうしていました)、現在はそのようなプロンプトはやめました。
理由は後続のBIツールで可視化する際に、例えば円グラフなどで件数が少ないものがまとめられるその他と、明示的に付与したその他の判別がつかなくなったからです。
分類
続いて分類を設定していきます。分類は独自に作成したカスタムフィールドであり、問い合わせの内容を文字通り分類するもので”質問”と”依頼”のいずれかから選択します。
以下のようにChat GPTの Classify Text で問い合わせ内容を質問か依頼に仕分けします。
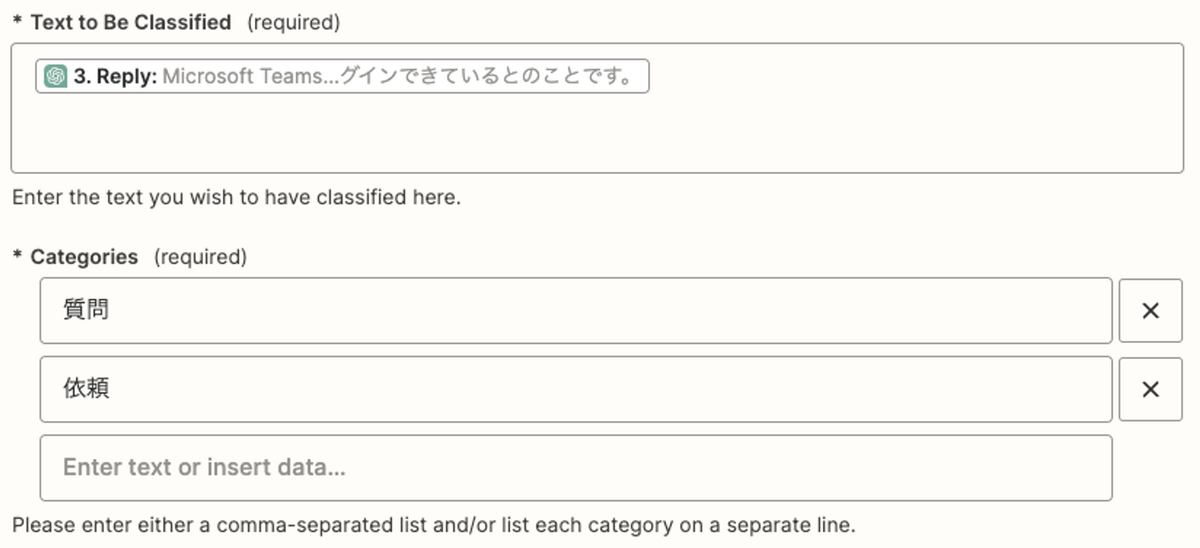
このようなJiraで選択肢があるフィールドはこのままではZapierから投入することはできません。”質問”と”依頼”はJira上ではそれぞれ別のIDを持っており、Zapierから指定するにはこのIDを指定する必要があります。
それぞれの選択肢のIDの値はZapier上から確認できます。ZapierのJiraのアクションから対象のIssueを選択し分類を見ると以下のようになっているのでこの数値がIDとなります。
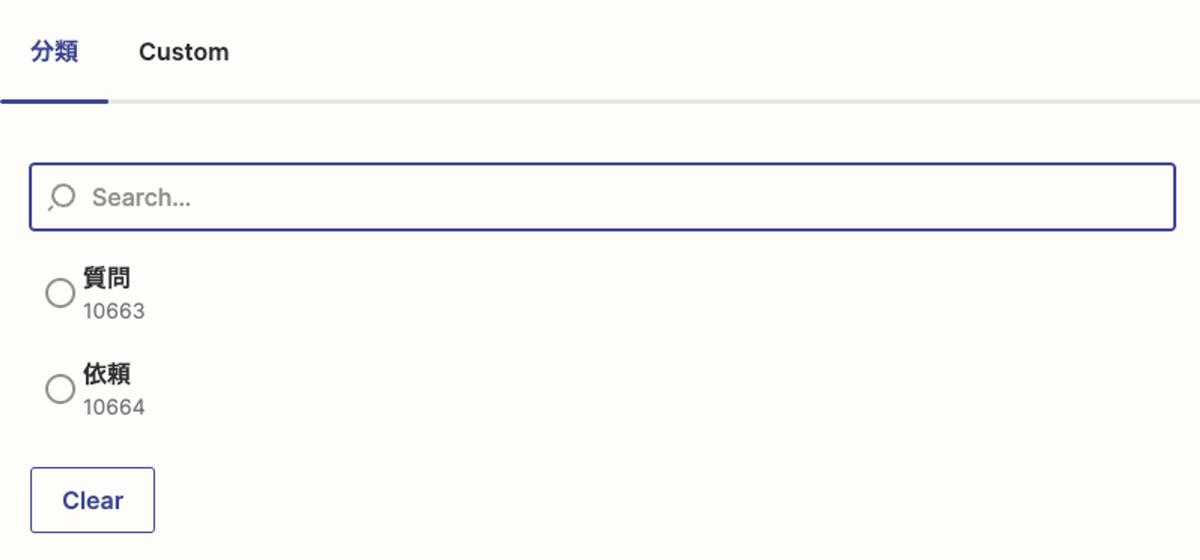
LLMで分類した値をこれらのIDに変換するためいくつか方法がありますが、今回は Utilities を使います。
Zapier UtilitiesのLookup Tableを使ってChat GPT Actionで生成した文字列をIDに変換します。
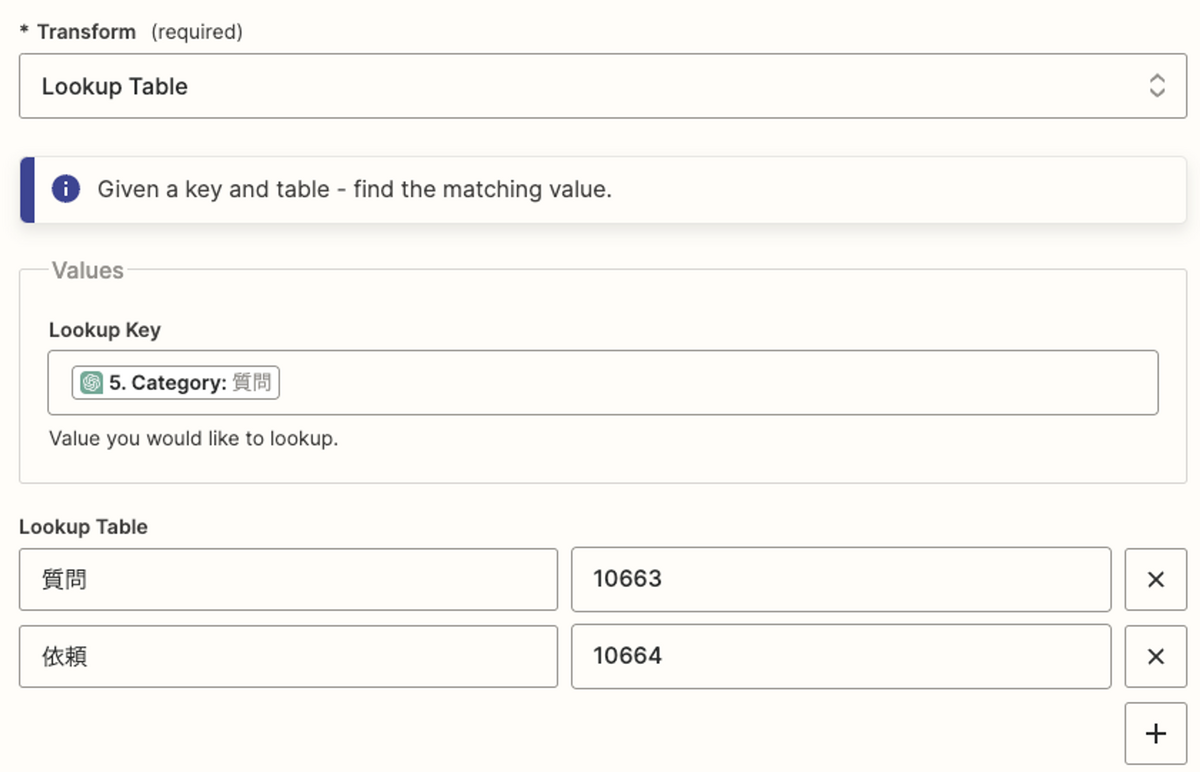
項目の追加や削除があった場合にはここもメンテナンスする必要があるため、その点はご注意ください。
これでJiraに設定するための値が出揃いました。
Jiraチケットの更新
要約、説明、タグ、分類が用意できたので、Update Issue in Jira Software Cloud のUpdate Issueを設定します。
IssueにはWebhookで受け取ったKeyを指定します。

要約・説明・タグ・分類には上記で生成した結果を設定します。


最後に 必須項目である報告者にWebhookで受け取ったreporterを設定すればOKです。

これで問い合わせ内容をもとにした自動属性付与の流れが完成です。任意の問い合わせチケットを生成して値の精度を確認しながらプロンプトを微調整してください。 なお、あくまでも生成自体は補助的なものであり、どこかで人がチェックする運用にしておくほうがより安全かつ確実です(特にタグ)。
BIツールに連携
Jira Service Managementに蓄積したデータはそのままJiraのダッシュボードで可視化することもできますが、利用できるガジェットが限られています。またJira以外のデータも含めて横断的に表現できることからLooker Studioに連携していきます。
Step1. Googleスプレッドシートに同期
Looker Studioにデータを連携するに当たってまずはGoogleスプレッドシートにデータを同期させます。方法はいくつかありますが、ノーコードでありAtlassianが公式に提供しているスプレッドシートのアドオンJira Cloud for Sheetsを使います。
JQLで必要なチケットの抽出、列の選択に加えて、定期実行なども設定できます。使い方の詳細は以下を参照ください。
Step2. スプレッドシートをLooker Studioで可視化
スプレッドシートに蓄積したデータをLooker Studioにデータソースとして追加し、あとは任意のグラフを追加して可視化していきます。
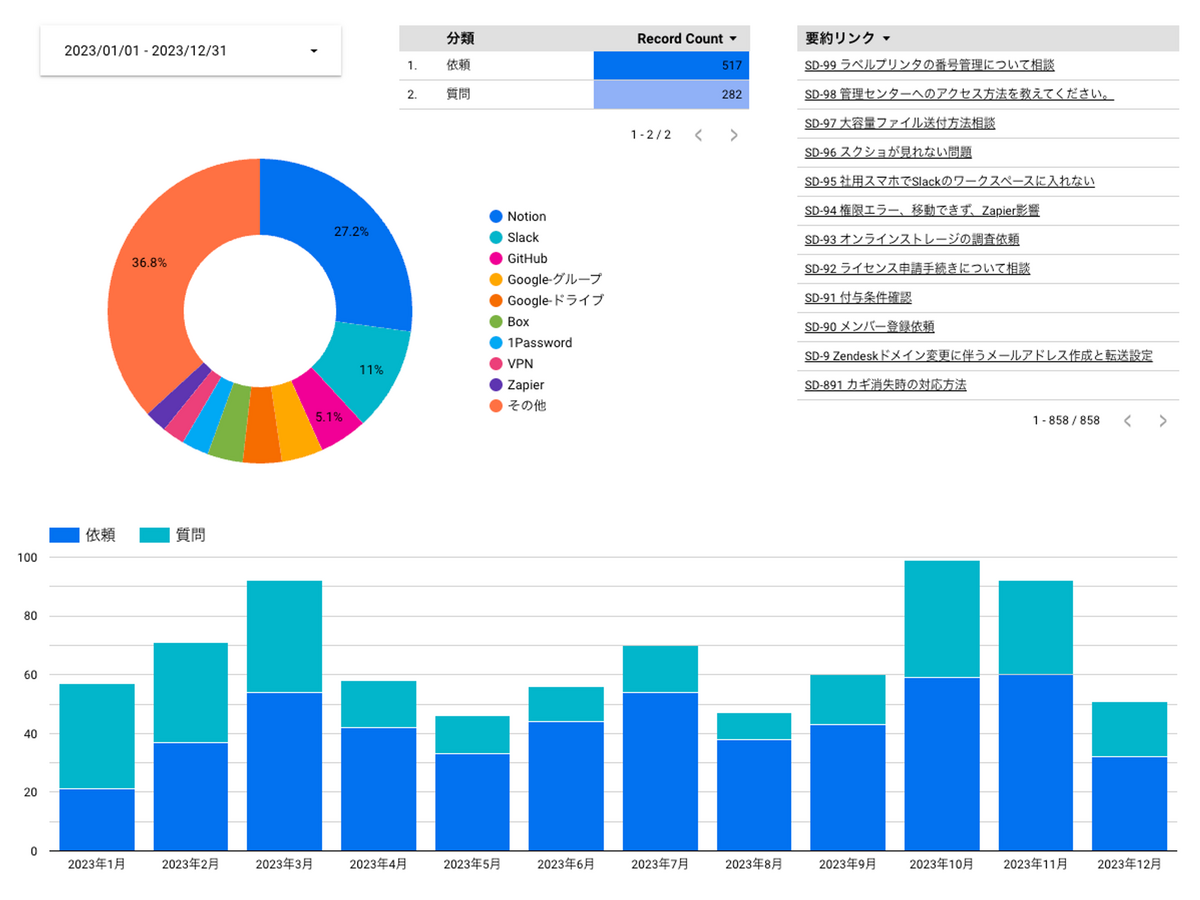
これで常に最新のデータで可視化されたダッシュボードが完成しました。このデータを元に、振り返りでは依頼・質問それぞれの件数とタグの割合を見ながらネクストアクションを考えていきます。
例えば依頼の多いタグに関しては、依頼自体を別途フォームとして用意して効率化できないかを検討したり、質問が多いタグに関しては、ドキュメントの在り方・導線・周知方法などに課題がないかを検討していきます。
また、半期・四半期で組織変更時などは特に質問などが増えるなど組織ごとの特性が見えてくるため、それらを織り込んだ作業計画に繋げられます。
余談. 要約リンク
Jiraのダッシュボードの場合グラフをドリルダウンしてチケットの詳細を確認することができますが、Looker Studioの場合そのままでは実現できません。 そこで以下のような計算式のフィールドを用意しシンプルな表を用意すれば、任意のフィルタ条件で一覧化し、かつチケット詳細に飛ぶ流れが実現できます。
HYPERLINK(CONCAT("https://[Atlassianインスタンス名].atlassian.net/browse/",キー),CONCAT(キー," ",要約))
まとめ
ここまで、LLMを活用して問い合わせデータの蓄積を効率化し、改善サイクルを円滑に回すためのデータフローについてご紹介しました。特に重視したのは、データの蓄積と、そのデータを用いた改善プロセスです。このアプローチにより、より効果的なデータ駆動型の施策を検討することができます。
現在もなお試行錯誤を続けており、プロセス自体にはさらなる改善の余地があるものの、このブログが類似の課題に直面している他の組織や個人にとって、役立つものとなれば幸いです。