
こんにちは。Reliability & Securityチームに所属するSoftware Engineerの@sota1235です。
今回は10X内における障害対応プロセスの改善をご紹介します。
今が完成系ではなく道半ばではありますがこの半年 ~ 1年で大きく進化したので同じくらいのフェーズの会社で困ってる方がいたら参考にしてみてください!
ちなみに私ごとですが去年の5/26にこんな投稿をしてたのでやっと伏線を回収する形となります(※ ドヤ顔ではありません)。

目次
こんな感じで紹介していきます。
障害対応プロセスの改善に踏み切った背景
障害対応の改善に踏み切るまでの10Xの障害対応のスタイルは以下のような感じでした。
- Slackで全社員が属する障害対応チャンネルを作り、そこで障害対応活動を行う
- 対応が込み入る場合は各自の判断で別チャンネルの作成等を行う
- 障害報告のフォーマットや基準等はなく、「小さな異常でも気付いたら誰でも報告してください」スタイル
- 報告の基準はふんわり決まっていたが、対応手順や進め方はフリースタイル
- 障害対応が完了したら障害報告書を書く
当時のプロダクトチームは30人いないくらいの規模感だったのでこれで問題なく機能していました。
しかしサービスの成長、それに伴う会社の規模拡大に合わせて障害対応プロセスの課題が徐々に浮き彫りになってきました。
課題1. 障害の報告フォーマットが統一されていない
障害を報告する際のフォーマットが人により異なり、第三者から見た時に何が起きているのか把握するのが困難なことがありました。
障害対応の際は報告を見たメンバーがどのように動けばよいか判断するために以下の情報等を共有すべきです。
- 発生している事象は何か
- 誰にどこでどんな影響が発生しているのか
- 原因はわかっているか
- ステータスはどうなのか(すでに対応しているのか、調査中なのか etc...)
- 契約パートナーへの報告は行うべきか
このような情報が共有されるケースもあれば、実は別チャンネルのSlackスレッド上で対応が進行していたり、Google Meetで対応が進行しているケース等がありました。
障害対応はスピードが大事ですが、最低限の情報は障害対応チャンネルに共有されるよう改善する必要がありました。
課題2. 障害報のクオリティの差異が大きく後から振り返りが難しい
障害対応が完了した後は障害報告書を書く運用になっていましたが、この障害報告書の更新状況に差異がある状況でした。
障害は発生しないことが一番ですが、発生した場合にはその情報をまとめ上げ振り返りを行うことで会社の大きな資産になります。
しかし障害報告書の内容に不備や不足する情報があると振り返りが難しくなり、当時の情報が失われます。
障害報告書、および振り返りに価値があることに関してはSRE本のPostmortemの話が有名なのでリンクを貼っておきます。
課題3. 障害対応者が特定の人に偏る
会社の規模が拡大することによりプロダクトチームの人数は徐々に増えていたのですが、一方で障害対応をLeadするメンバーが固定化されつつあり負荷が偏っていました。
そうなってしまう理由を探っていくと「障害対応に参加はしたいが進め方がわからない」というIssueがあることが分かりました。
障害対応時には障害に関連する機能に詳しくなかったとしても舵取り役(いわゆるIncident Commander)として動いてくれる人がいることで効率よく進めることができます。
しかし当時は定められた障害対応の進め方は存在せず、対応を支援するような情報もNotion上に散らばっていました。
結果としてサービスに詳しく10Xでの社歴が長い、もしくは障害対応の経験が豊富なSoftware Engineerがボールを拾いがちな状況に陥ってました。
第一の改善
上記の課題を解決すべく、まずは2つの改善策を打ちました。
改善1. 障害報告書のフォーマット更新
まずは障害報告書のフォーマットを更新しました。
元々、Notionのテンプレート機能を利用して運用されていたフォーマットがあったので以下の改善を行いました。
- 以下の項目を記入するようにした
- タイムライン
- 発見経路
- 影響範囲
- 原因
- 一次対応
- 再発防止策
- 各項目に具体例・解説を記入する
2つ目の具体例・解説を記入するのがミソで、これにより個人個人の解釈によるフォーマットのブレや情報濃度の差分を減らすことができました。

改善2. Slack Workflow / Zapierによる報告フォームの導入
Slack Workflow、Zapierの連携により以下の機能を持つフォームを実装しました。一番最初の改善スタートとしては「なるべく工数をかけずに改善する」だったので、これらのツールを活用することにしました。
フォームは以下の順序で動作するようになっています。
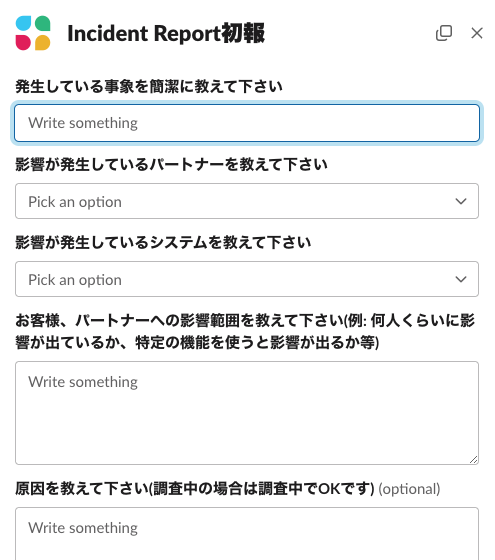
1. Slack Workflowで報告フォームを作成
報告フォームは障害対応チャンネルでslash commandにより起動できます。
2. 報告された障害の概要を障害対応チャンネルに投下する
フォームで投稿された内容を障害対応チャンネルに投下します。
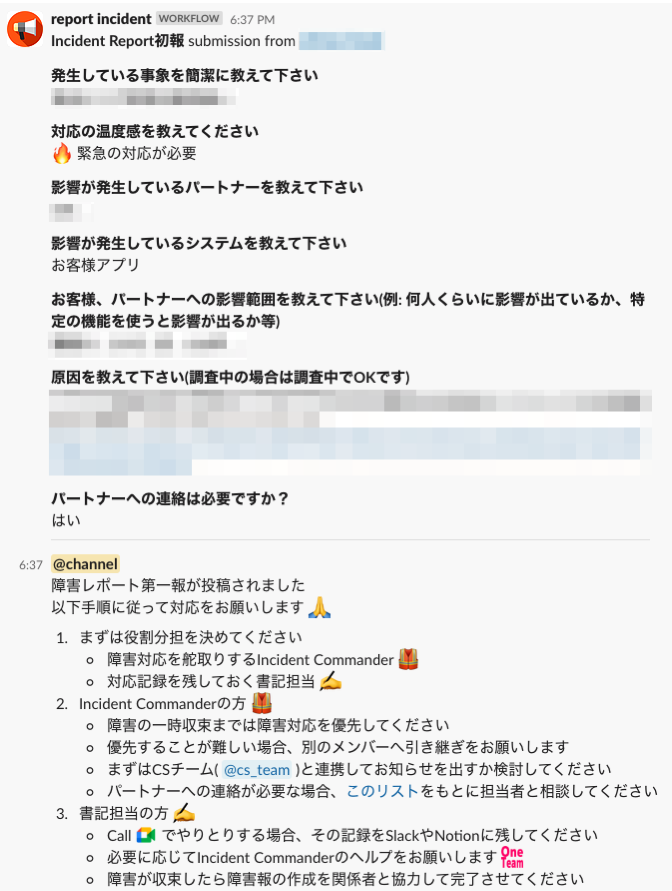
この際、障害の情報と合わせて障害対応手順や対応時に役立つリンクも合わせて投稿します。これにより障害対応の手順に迷わなくするのが狙いです。
3. 障害の内容をGoogle Spreadsheetに追記し、ZapierでNotion上に障害報告書を自動生成する
Slack Workflowの機能により、投稿された障害の情報をSpreadsheetに行として追加。Zapierでそれを元にNotion上に障害報告書を自動生成しました。
これにより障害報告書の作成漏れ、テンプレートの使用忘れを防ぎます。
改善による効果
障害報告書のテンプレートの改善、Slack Workflowの導入により以下の点が改善されました。
- 障害報告書の情報不足が改善され、資産として活用できるようになった
- 障害報告時のフォーマットが統一され、初動で何をすべきか分かりやすくなった
- 第三者が見たときに障害対応に協力できるかの判断がしやすくなった
- 障害報告書の作成漏れが減った
第一の改善である程度よくなったが…
当然ですが改善後、全てがうまくいったわけではなくいくつかの課題がありました。
またさらなるサービスの成長に伴い新たな課題も顕在化しました。
新課題1. 障害対応チャンネルの混線
近いタイミングで複数の障害が発生した場合、もしくは障害対応が長引いてる際に別の障害が発生した際に障害対応チャンネルが混線するということが多く発生していました。
複数の障害対応が1つのチャンネルで行われると対応者以外は何が起きているのか、それぞれの障害がどのようなステータスなのかが分からず混乱する状況でした。
また、そのようなケースでチャンネルを分ける判断をするメンバーもいましたが公式にはルール化されておらず、またそのチャンネルに誰を招待するかもメンバーの匙加減によるところが大きく重要な情報を見落とす可能性が存在する状況でした。
新課題2. 障害対応の手順が分かりづらい
Slack Workflowの導入によりどのような手順で障害対応を行うかは文面で共有されていますが、迷いなく対応を進めるにはあまり親切な自動化ではありませんでした。
ある程度慣れていたり、対応のイメージが湧いているメンバーには効果的でしたが障害対応の経験が浅いメンバーには依然としてハードルがありました。
新課題3. Slack Workflow、Zapierの自由度が低い
運用を続けていく中で障害報告書のテンプレートの改善や、障害報告フォームの改善要望が上がってくることがありました。
その際にSlack Workflow、Zapierの自由度が低く要件を満たせないことがありました。
例えばその障害で影響が発生しているシステムが複数ある場合は複数選択がしたい、という要件があってもSlack Workflowではそれが実現できませんでした。
また、Zapierの設定は癖があり設定者以外がいじるのが難しく属人性が高い状況でした。
第二の改善 Incident Botの誕生
新たな課題に対応すべく、初期の改善では見送った選択肢であるSlack App Directoryの実装を決意しました。
そう、Incident Botの誕生です。
Incident Bot誕生のきっかけ
きっかけは、チーム内でGMOペパボさんで内製されているIncident Botが話題になったことでした。
これを見たとき、10Xで感じている課題と共通点が多いこと。それを解決するための機能がよく考えられており、GMOペパボ社で実際に実績があることの2点から素直に「10Xにも同じようなBotが欲しい」と考えました
欲しいなら作ればいいじゃない
欲しいなら作ろう、エンジニアなのだから。そういうわけで10XなりのIncident Botの開発を行うことにしました。
まず基本機能はGMOペパボ社の事例を参考にしつつ、10Xで必要な要件を組み込み開発する機能を決めました。
機能を検討する
10Xで当時抱えていた機能を改善すべく、ざっくり以下の機能を実装することにしました。
- よりリッチな障害報告用のフォーム
- 障害対応用のチャンネルの自動生成
- インタラクティブな障害対応のサポート
- 障害報の自動生成
- 障害ステータスの変更機能、および然るべきチャンネルへの情報共有
実装する
実際の実装は以下の技術スタックで行いました。
細かいところは省略しますが、ディレクトリ構成やライブラリは拙作のboilerplateとほとんど同じなので興味がある方は見てみてください。
デプロイはGitHub Actionsで行えるようにし、StagingとProductionを用意。Stagingは手動で任意のブランチをデプロイできるようにしました。
実際のBotの様子
実際に障害報告を行なってから収束するまでの流れを簡単にご紹介します。
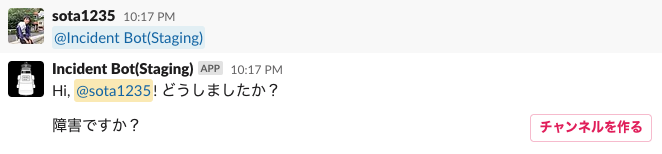
障害の報告
Botにメンションすることによりチャンネル作成の案内がされます。
チャンネルを作るボタンを押すことでフォームが表示されます。
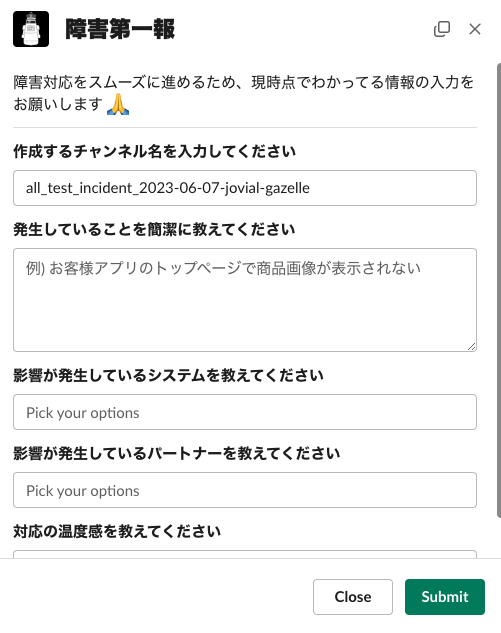
フォームの内容はGMOペパボさんの事例を参考にしつつ、必要最低限の情報のみを記入するよう項目をなるべく絞っています。Slack Workflowでは実現できなかった複数選択やフォームに自動生成されたチャンネル名を入れる等の処理が可能になりました。
対応の温度感は最初は4段階でしたが、利用者のfeedbackを元に3段階にしています。
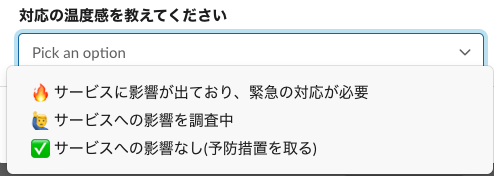
チャンネルの自動生成
フォームを入力後、その情報を元にチャンネルが作成されます。

作成されたチャンネルには障害レベルに応じてメンバーが自動招待されます。招待メンバーはSlack User Groupに基づいて行われます。
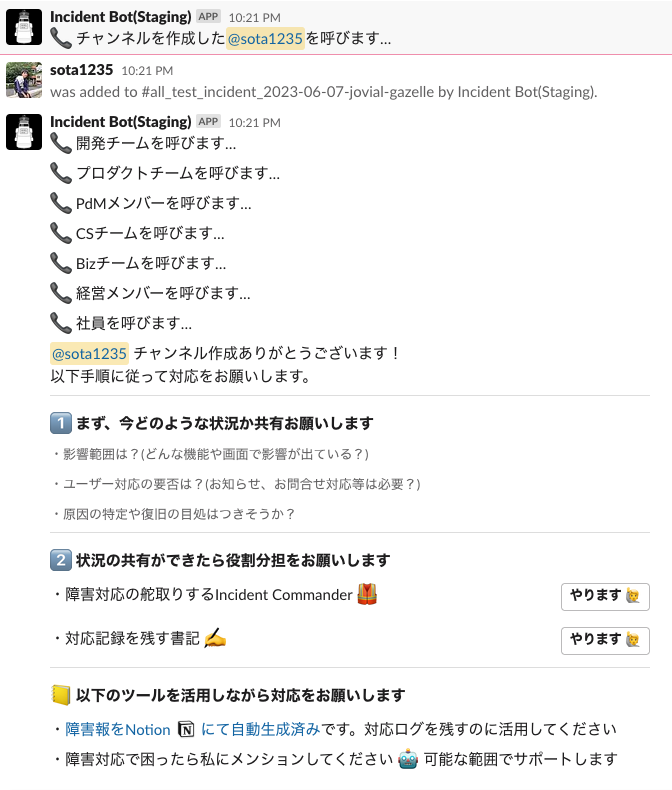
チャンネルでは障害対応の進め方をなるべくシンプルに案内します。
インタラクティブなサポート
Incident Commander、書記のやります 🙋ボタンを押すコトでそれぞれの役割に求められることがBotから案内されます。

対応中、困ったことがある場合はBotにメンションすることでいくつかの機能が利用できます。
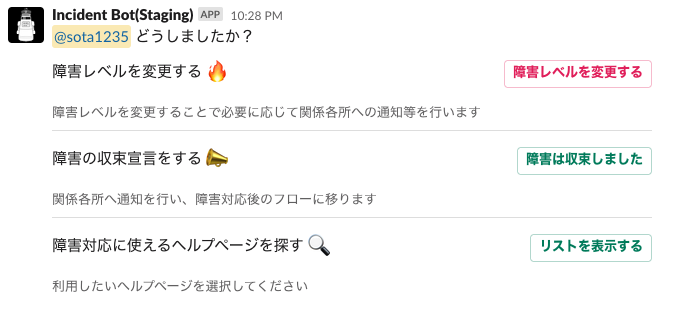
障害の収束を宣言する
障害の収束宣言を行うことで収束後の案内が表示されます。
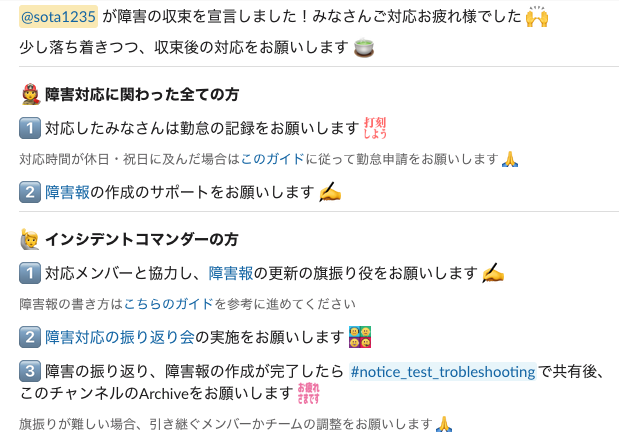
障害対応後に忘れがちなTODOを案内します。また、振り返り会の実施も促します。
Incident Bot導入による効果
このBotの導入により以下の課題が解決されました
- 障害対応がチャンネルごとに分離され、混線することがなくなった
- 障害対応のLeadのハードルが下がり、障害対応者の属人化が緩和された
- チャンネルが分離されることで障害後の振り返りも進めやすくなった
合わせて取り組んだこと
よりリッチなBotを実装したことは1つの成果ですが、使われなければ意味がありません。
何かの課題解決を狙う機能を作ったらオンボーディング戦略も合わせて考えることが重要です。
そのため、Botのリリース後は障害対応マニュアルの刷新と全社への周知を徹底しました。
また、実際に利用される場面でつまづきどころがないかを観察し、必要に応じてサポートや機能の宣伝を行いました。
今後の課題
Incident Botのメンテナンスコスト
ご存知の方も多くいると思いますが、今回実装したBotのような機能を提供するSaaSが実は多く存在します。
今回、10XではBotがどれくらい機能するか予想が難しく、小さく始めたいというモチベーションがあったので自前での実装に踏み切りましたが今後のメンテナンスコストの向上や障害対応プロセスの進化に合わせて外部サービスを利用する選択肢も頭に入れておく必要があります。
とはいえ現状は問題なく機能しており、細かい改善を重ねながら当分はこのまま使い続けることができると考えています。
障害を自分ごと化してもらうための作り込み
現状のIncident Botの実装では障害レベルが高い場合は全社員を容赦なくinviteする等、大味な実装になっている部分が多いです。
緊急時には社内のメンバーを大きく巻き込むことは大切でありつつも、関係ないのに常に巻き込まれ続けると障害対応自体への関心が薄れてしまう可能性があります。
運用しながら様子を見つつではありますが、なるべく障害に関係しうる人を適切に巻き込むような作り込みが必要そうだなと考えています。
最後に
障害対応のプロセスはサービス、組織の成長に合わせて進化が求められます。
今回紹介した改善はプロセス改善の旅の第一歩目に過ぎず、今後も継続的に改善していく必要があると強く感じています。
私たちがGMOペパボ社の事例から学んだように、10Xの事例がどこかの組織の障害対応プロセスの改善に役立てば幸いです。