こんにちは、検索エンジニアの安達( 負荷に合わせてElasticsearch(ElasticCloud)をスケーリングする機能を作りコスト削減したので、その取り組みについて経緯と内容を紹介します。 10Xでは小売チェーン向けECプラットフォームStailerにおいて、検索機能の開発運用にElasticsearchを利用してしています。
Elasticsearchクラスタの基盤にはElasticCloudを採用していますが、ディスク利用量に応じたオートスケール機能しかなく、メモリ利用量やCPU利用量に基づくオートスケーリングはできません。
そのため、負荷が少ない時間帯でもピークタイムのリクエストを処理できるクラスタを稼働させる必要がありました。 また、日に日に負荷が増え続けている影響で、最近インスタンスサイズをスケールアップしないと安定した運用ができなくなりました。
これによりコストが約2倍になり、何らかの対応が必要になりました。 リソース利用率に合わせてElasticsearchをスケーリングすることで解決しました。
他の打ち手の候補として、データ更新の時間をずらす、データ更新の速度を落とす、インデックスのデータ構造・設定の変更がありましたが、調整によるリードタイムや工数が大きかったり、効果の不確実性が高かったため見送りました。 StailarのElasticsearchはCPU boundです。
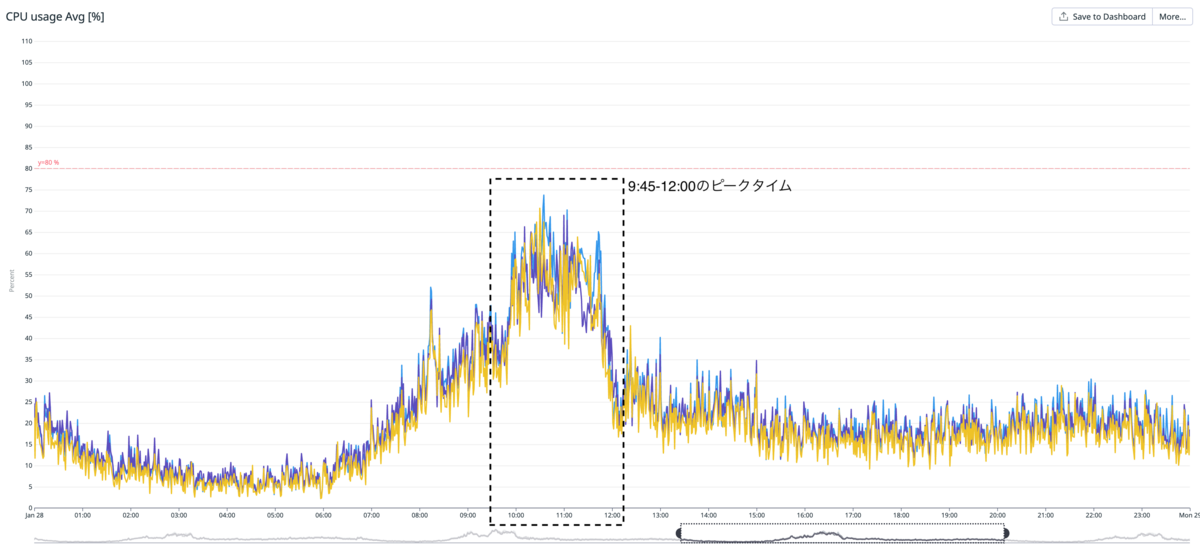
検索リクエストのピークタイムが8:00 - 12:00、更新リクエストのピークタイムが9:30 - 12:00で重なっており、結果的に CPU利用率 のピークタイムは 9:30 - 12:00になっています。
細かいデータ更新は常にあるものの、スーパーやドラッグストアの在庫データを一括で更新するバッチが日次かつ定時で動いており、更新リクエストのピークタイムは固定です。 以下はCPU利用率のメトリクスです。
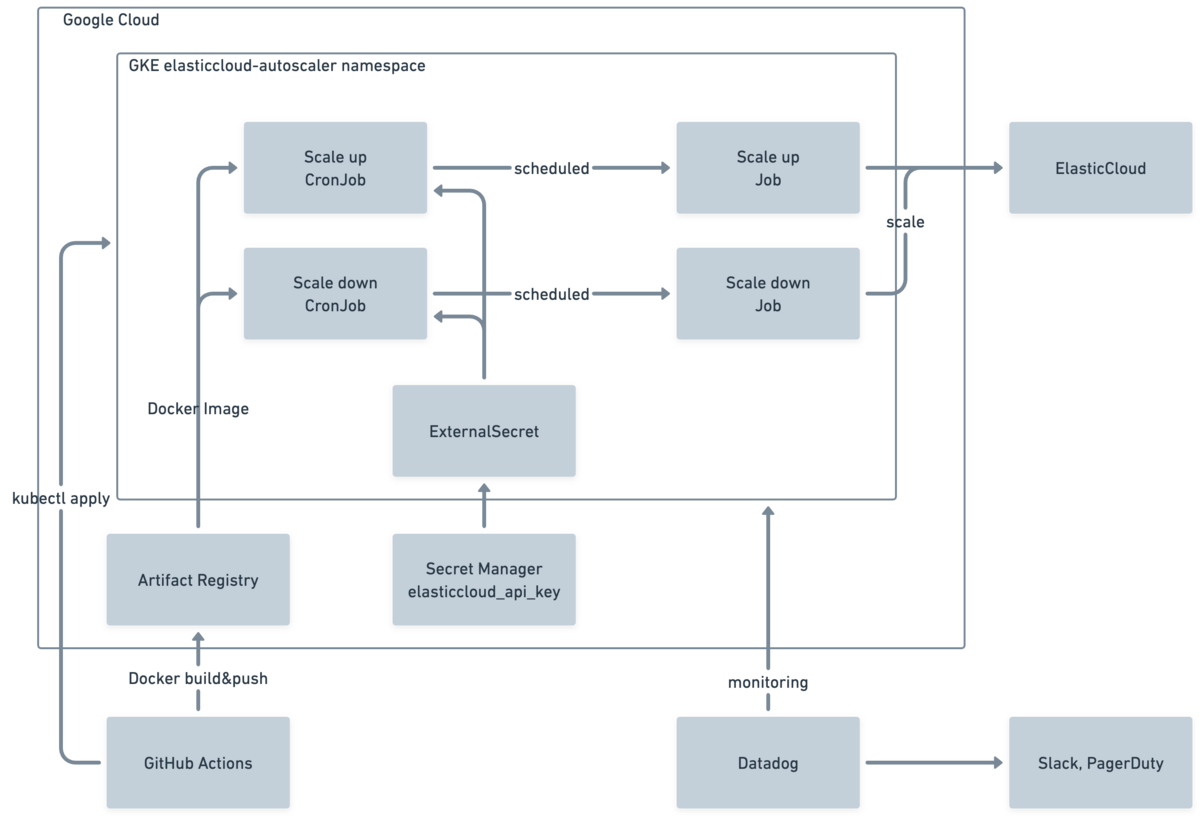
縦はCPU利用率、横は時刻です。 検索・更新リクエストのピークタイムが被る9:45~あたりからCPU利用率が急上昇します。 ノード数を増減させるスケールイン・アウトではなく、ノードスペックを増減させるスケールアップ・ダウンを採用しました。 理由 スケジュールトリガーを採用しました。 理由 cloud-sdk-goを利用したGoスクリプトをDocker ImageにしGKE CronJobで実行し、定期的なスケールアップ/ダウンを実施しました。 アーキテクチャ図は以下です。 他の選択肢とPros/Consは以下です。
#2を採用しました。 スケールアップが失敗すると、検索機能に障害が発生する可能性が高く、高い可用性が必要です。
しかしGitHub ActionsでのCronはこれまでの実績的に信頼が低いため、#1は選びませんでした。 また、当初Cloud Scheduler → Pub/Sub → Cloud Functionsも選択肢に入れていましたが、timeoutが最大10分なので選択肢から棄却しました。
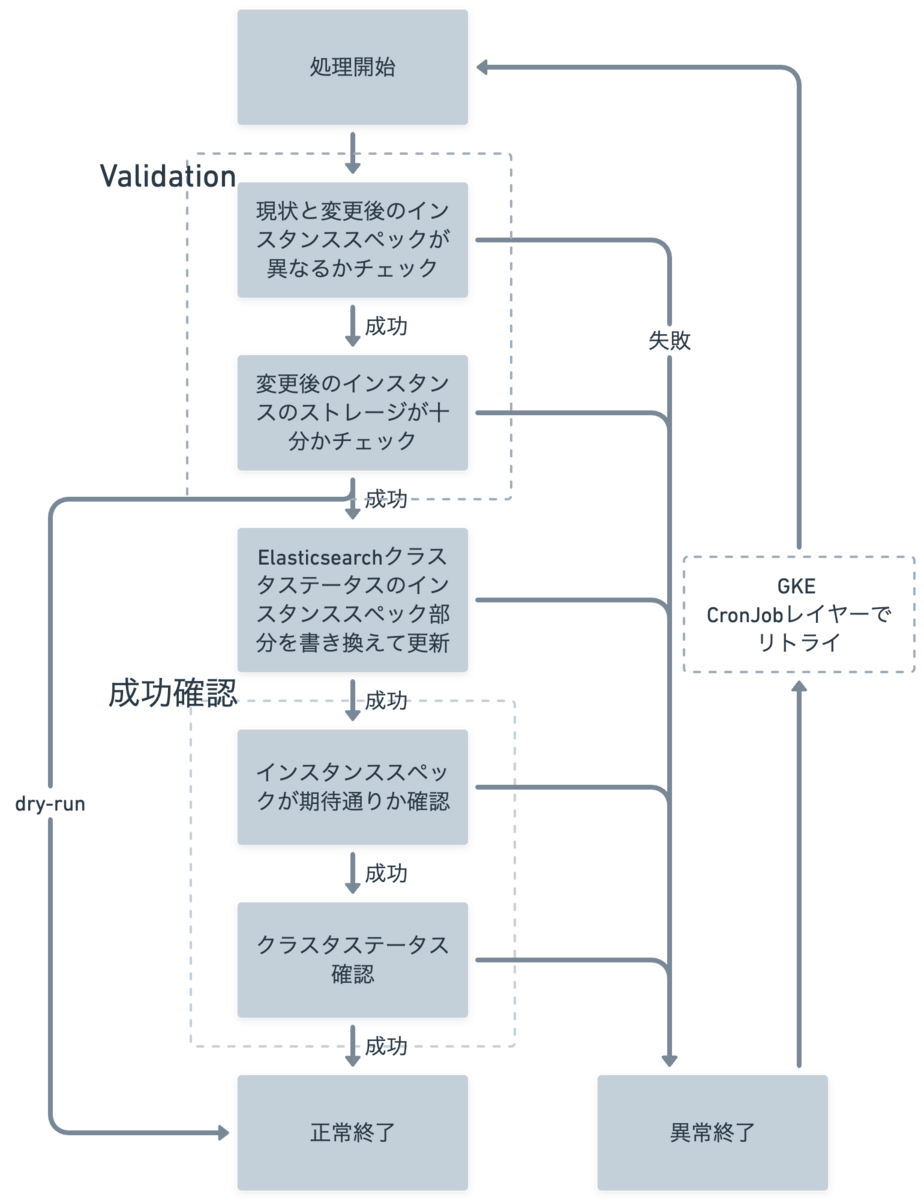
スケーリングは10分以上かかってしまうので、成功確認できず失敗した時の検知やリトライの仕組みを別途作る必要がありました。 処理の流れは以下です。 注意すべき点は2点あります。 スケールアップが失敗すると、弱いスペックのノードのまま高負荷状態を迎えることになります。
これによりElasticsearchがパンクし検索機能が動かなくなり、大きなユーザー影響につながるかもしれません。 CronJobでリトライを設定しJobの失敗はリトライするようにし、複数回失敗した場合にはDatadogで検知しSlack + PagerDutyで通知するようにしました。
実際に、リリースしてから3日後にElasticCloudの偶発的な問題によりスケールアップが失敗しリトライが走ることがありました。
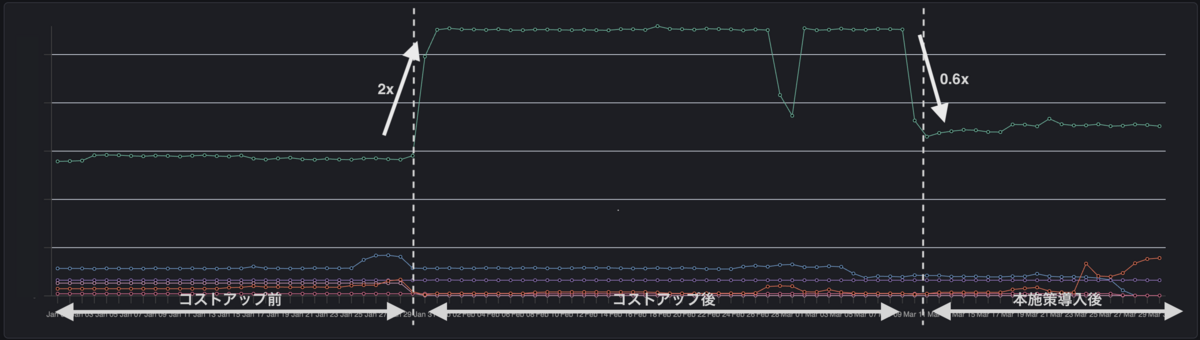
リトライを設定しておいて良かったです。 本施策により、本番Elasticsearchクラスタのコストを40%程度削減できました。
以下のグラフは、縦軸がElasticsearchクラスタごとのコスト、横軸が時間です。 緑の折れ線が対象のElasticsearchクラスタです。
元々のコストが左の区間、その後スケールアップしコスト増加したのが中央の区間、本施策導入後が右の区間です。
中央の区間で一時的にコストが下がっているのは、別の施策を試してみたが上手くいかなかったので戻した痕跡です。 また、本施策導入後もサービス品質を落とさずに運用できています。 余談ですが、Elasticsearch 7.17から8.12へアップデートも最近実施したのですがパフォーマンスが向上しさらにインスタンスサイズをスケールダウンできコスト削減できました。
おまけにレイテンシーも良くなりました。
はじめに
![]() id:kotaroooo0)です。
10Xで検索基盤・検索機能の開発運用をしています。
最近は推薦システムの開発もちょっとやり始めました。
id:kotaroooo0)です。
10Xで検索基盤・検索機能の開発運用をしています。
最近は推薦システムの開発もちょっとやり始めました。前提
背景と課題
対応方針
StailerのElasticsearchに関する特性
要件
スケールイン・アウトではなくスケールアップ・ダウン
リソース負荷トリガーではなくスケジュールトリガー
設計
#
スケール方法
定期実行方法
Pros
Cons
選択候補になった理由
1
Terraform + GitHub ActionsでPull Requestマージ
GitHub Actions
• 宣言的に管理
• Extensionsもコード管理できコンソールでの手作業が減る
・現状ElasticCloudのTerraform管理していないし、PR自動作成&マージは工数大
・GutHub ActionsのSLAに不安あり クラスタのスケールアップ・ダウン方法はTerraformが一番良いと考えた。Pull Request作成&マージはGitHub Actionsが親和性が高い。
2
cloud-sdk-go
GKE CronJob
・既存で多くCronをGKEで動かしており運用しやすく可用性も安心
・Go(プログラミング言語)で操作できる
・Go用のDocker ImageのBuild/Deployを実装する必要あり
クラスタのスケールアップ・ダウン方法はTerraformの次点でcloud-sdk-goと考えた。GitHub Actionsと親和性がない方法にするのであれば別の定期実行方法にしたい。
3
cloud-sdk-go
Cloud Functions + Cloud Scheduler
・CloudSchedulerはマネージドであり可用性が高い
・モニタリング・監視もしやすい
・Go(プログラミング言語)で操作できる
Cloud FunctionはGoランタム対応 ・CloudSchedulerはこれまで利用されておらず、管理対象が増える
・処理時間の要件上、Cloud FunctionsをHTTP経由でフックするしかなくその場合デプロイが複雑
・長時間Functionsを動かす必要がありGoogleが期待するFunctionsの用途からずれていそう 同上
cloud-sdk-goでの処理
モニタリング
おわりに