
お久しぶりです。SRE の @babarot です。2022年4月に書いた 10X に SRE Team ができるまでとこれから 以来、3年ぶり2度目の文章です。10X に SRE チームができてから3年以上が経ち、その間の活動や成果などについて沈黙しまくっていたのですが、振り返ると実に多くのことを達成してきました。最近は会社的にも嬉しいニュースがあり、これから更にやっていくぞ 🔥というフェーズに来ております。この3年間、黙々と頑張りすぎてアウトプットがなかなかできていなかったので、このブログ記事ではこれまでの SRE の取り組みを軽く紹介しつつ、今後はそれぞれのテーマに深ぼったネタを定期的に記事にして投稿してきます!まずは第1弾として2025年時点の 10X SRE の現状報告ブログをどうぞ。
10X インフラの歴史
具体の事例紹介の前に10Xではどんなアプリケーションを扱っていて、どのような構成で動いているのかを説明します。
10X では Stailer というネットスーパーの立ち上げ支援プラットフォームを作っています。これはどこかのスーパーやドラッグストアなどの小売店、もしくはその事業者が「うちも EC やりたい!」となったときに、その会社の事情にフィットしたクライアントアプリ・Web・商品マスタ設計・配送アプリ・スタッフアプリ・管理画面アプリなどの必要アプリ群をまとめて提供するというサービスです。EC をやりたい会社が名乗りを上げて Stailer に乗っかることで各社が必要とするネットスーパーの機能をオプトインしながら Easy に参入できる、こういった世界を目指しています。
2020年、Stailer の誕生以来、10X では Google Cloud (GCP) をメインに据えたアーキテクチャで、現在もなおインフラは GKE、クライアントは Flutter (Dart)、サーバも Dart、サービス間通信は gRPC、認証やデータベース Firebase/Firestore、モニタリングは Datadog + PagerDuty というローンチ当初の基本的な構成は変わっておりません。
ちなみに、なぜこのような技術選定になっているのか?とよく聞かれますが、これはひとえに開発効率をあげるためでした。クライアントは Dart をベースとした Flutter で iOS/Android の開発を行っており、サーバは 100% Dart です。そのため開発者は Dart の言語さえ読み書きできれば API からクライアントまで一気通貫して開発することができます。書き手はもちろん、Reviewer になる読み手もコンテキストスイッチを減らせるのは少人数で効率よく開発するうえではとても良い選択だったと思います (当時のブログ)。Firebase/Firestore の選択も同様の理由です。Stailer ではネットスーパーの立ち上げに必要となるたくさんのアプリ群を各社ごとに作るため、Frontend/Backend とも Dart にして Firebase で開発スピードを上げようとなったわけです。
なおインフラに GKE (Kubernetes) を採用しているのは過去アーキテクチャの利活用のためです。10X は過去に一度ピボットしており、以前のプロダクト「タベリー」では GKE を使っていました。すでにクラスタがあったことや、開発メンバーの多くがすでに Kubernetes を使っており一定慣れていることや、GKE に設定されたモニターやアラートなど、過去の資産をそのまま流用できることから、そのまま踏襲して GKE が選ばれました。今となっては Cloud Run / Run Jobs など、よりリーズナブルな選択肢があると思います。
graph TB
subgraph "小売事業者"
A[スーパー・ドラッグストア等]
end
subgraph "Stailer Platform - 提供アプリ群"
C[クライアントアプリ<br/>Flutter/Dart]
D[Web アプリ<br/>Flutter/Dart]
F[配送アプリ<br/>Flutter/Dart]
G[スタッフアプリ<br/>Flutter/Dart]
H[管理画面アプリ<br/>Flutter/Dart]
end
subgraph "Google Cloud Platform (GCP)"
subgraph "GKE Cluster"
L1[商品管理サービス<br/>Dart Server]
L2[注文管理サービス<br/>Dart Server]
L3[配送管理サービス<br/>Dart Server]
L4[ユーザー管理サービス<br/>Dart Server]
end
N[Firebase/Firestore<br/>Database & Auth]
subgraph "Monitoring"
O[Datadog]
P[PagerDuty]
end
end
A -.-> C
A -.-> D
A -.-> F
A -.-> G
A -.-> H
C --> L1
C --> L2
D --> L1
D --> L2
F --> L3
G --> L1
G --> L2
H --> L1
H --> L2
H --> L3
H --> L4
L1 --> N
L2 --> N
L3 --> N
L4 --> N
L1 -.-> O
L2 -.-> O
L3 -.-> O
L4 -.-> O
O --> P
宣言的なインフラ管理
インフラの構成管理 (Terraform)
10X では複数のアプリケーションとそのインフラを各パートナー企業ごとに提供をしています。この「インフラをパートナーごとに準備する」という部分が特徴で、各社ごとに専用の Google Cloud プロジェクト (prod/dev) を作成し、そのプロジェクト上に Stailer に必要な各種リソース (GCS や Cloud Pub/Sub、DNS など) を作成しています。Stailer を利用してくれるパートナー企業が今では13社以上になり「パートナー数 x 環境数」分のセットアップが必要となるため自動化が必須でした。また、インフラ管理におけるコード化は構成管理をレビュー可能にする、再現性を高めるという意味でもマストだと思います。
コード化には Terraform を使用していますが、plan や apply のために Terraform Cloud や Atlantis といったサービスは使わず、GitHub Actions で実装しています。terraform コマンドを実行する用の composite actions を作り、terraform xxx → notify のような一連の処理をパッケージングして使っています。
各パートナーのインフラをセットアップするために Service Kit (tfmodule-service-kit) という Terraform Module を作成しています。このモジュールをソースに tf ファイルを書くと、パートナーのローンチに必要なプロジェクトとインフラリソースがまとめて作成されます。
graph TB
A[Terraform Module<br/>tfmodule-service-kit]
subgraph "各パートナー企業への展開"
E[パートナー企業A] --> F[Project A]
G[パートナー企業B] --> H[Project B]
I[パートナー企業C] --> J[Project C]
end
subgraph "パートナーA のリソース"
M1[GCS]
N1[Datastore]
P1[その他リソース]
end
subgraph "パートナーB のリソース"
M2[GCS]
N2[Datastore]
P2[その他リソース]
end
subgraph "パートナーC のリソース"
M3[GCS]
N3[Datastore]
P3[その他リソース]
end
A -.->|モジュール適用| F
A -.->|モジュール適用| H
A -.->|モジュール適用| J
F --> M1
F --> N1
F --> P1
H --> M2
H --> N2
H --> P2
J --> M3
J --> N3
J --> P3
モジュールの設計思想は Deep Module, Smart Default です。Terraform Variables/Outputs はインターフェイスになるため変数として公開するものは最小限にし、また複雑な設定をせずとも最適なサービスローンチが実現できるように実装しています。この設計指針によって、モジュール利用者は最低限のインターフェイスにのみ向き合えばよく、モジュール開発者としても複雑な validation などで入力を制御する必要がなくなり、お互いにとって好都合です。
個人的にですが、会社独自に成長した CLI ツールやそのコマンドオプション、設定ファイルやそれ前提のスクリプト、この Terraform Module もそうですが、ドメイン知識を多分に盛り込んだインターフェイスに開発者を付き合わせることはあまりいいことではないと考えています。こういったドメイン知識前提の設定は新参者に厳しく、また SWE としての成長スキルとも無縁だったりすることも多いため可能な限り隠蔽してあげるのが良いかなという判断です。とはいっても完全には難しく、できる範囲での努力ですが..! (加えて 10X では Module の内部事情を理解して Module 側に PR を作ってくれる人も多かったりします)
以下は設定の例の一部です。よく使われる設定をデフォルト値として設定し optional で設定されるように提供しています。
module "stailer-babamart" { source = "git@github.com:10xorg/tfmodule-service-kit.git?ref=v0.13.2" service = { name = "stailer-babamart" environment = "production" members = ["xxx@10x.co.jp"] partner = { name = "babamart" site_type = 16 status = "LAUNCHED" } } gcp = { storage_config = { delivery_bucket = { cors = { origin = ["https://babamart-netsuper.stailer.jp"] method = ["GET"] } } } } web = { domain = "babamart-netsuper.stailer.jp" create_dns_record = true search_console_txt = "xxx" }
Service Kit のモジュールでは以下のようなものを作成しています:
- Datadog Monitor, 外形監視
- BigQuery Dataset、Dataset IAM Member
- Artifact Registry IAM Member (レジストリは中央管理のもの、IAMだけ付与)
- Cloud Run Job、Cloud Run Job IAM Member
- DNS関連
- Firebase Project
- Workload Identity 関連
- Log Sink
- Secret Manager、Secret Manager IAM Member
- Storage Bucket、Storage Bucket IAM Member
- Google Group
他にもありますが、このように ”特定リソース” + ”リソースレベルの IAM” までを1パッケージで作成できるため、新規パートナーが獲得できたらこのモジュール経由で Google Cloud Project を作成する PR を作るだけでいろいろなものがバルクで作成されるため便利です。
PR の作成も Actions にしており、workflow dispatch の Input に必要な項目を入力することでモジュール呼び出しの tf ファイルを自動生成され PR が作成されるようにしています。
サービスローンチ用のモジュールとして Service Kit を開発していますが、チームローンチ用に Team Kit (tfmodule-team-kit) も開発しています。このモジュールではチームが立ち上がったときに必要となるリソースセットを Service Kit 同様にバルクで作成しています:
- PagerDuty Team
- Datadog Team
- チーム所属の Datadog Monitor
- チーム所属の Datadog SLO
- チームが見るべき Datadog Monitor, SLO をまとめた Datadog Dashboard
- Google Group
- Slack Mention Group
- Slack Team Channel (Alert Channel)
- LaunchDarkly
などです。また、GitHub の設定や Repository 設定なども Terraform 化をしており、いろいろな設定を PR によって変更できるようにしています。Terraform だけでもブログ書けるネタが何個かあるため、今度別記事で詳しく紹介したいと思います。
ワークロードの構成管理 (Helm)
10X では backend RPC service や管理画面 frontend といった基本的なワークロードの多くは Kubernetes (GKE) に載せています。パートナーごとに必要な設定項目 (このパートナーにはこのNS機能を提供しているなどのフラグ) に違いはあるものの、基本的にはワークロードは共通です。Deployment や Service、CronJob などはパートナー間でテンプレート化できるものが多く、それらをまとめた Helm Chart を作り設定をパッケージングしています。tfmodule-serivce-kit と同じ考え方です。helm-service-kit という chart repository を作り、サービスのローンチに必要なワークロードをバルクで作成しています。
graph TB
A[helm-service-kit]
B[tfmodule-service-kit]
subgraph "パートナーA"
C[ワークロードA]
D[インフラA]
end
subgraph "パートナーB"
E[ワークロードB]
F[インフラB]
end
subgraph "パートナーC"
G[ワークロードC]
H[インフラC]
end
A -.-> C
A -.-> E
A -.-> G
B --> D
B --> F
B --> H
Helm パッケージにする前は生のマニフェストを管理していました。この Helm 化と移行は同じ SRE チームの @horimi がやってくれました。
OnCall 体制の構築
アラートの整理
SRE チーム発足後、インフラの Terraform 化と同時に既存アラートの整備とオンコール体制の構築にも取り掛かりました。これまで、1つのアラートチャンネルにいろいろな Integration 繋がり色々なアラートが流れていました。これではノイジーすぎるし、どのアラートを誰が見ているのか、誰が受け取るべきアラートなのかが分かりづらかったため以下のように整理しました。
まず、アラートを2つに分けて考えました。
- Actionable Alerts: 人間が即座に対応すべきもの
- Non-Actionable Alerts: 即座に対応しなくて良いもの。通知として知りたいもの
Actionable Alerts は昼間であっても夜間であっても Primary On-Call の人間が即座に対応すべきアラートを指します。一般的に重大なインシデントや損害を生む可能性があるものです。例えば「Service X で OOM Killed が発生していて調査と対応が必要」などが該当します。Non-Actionable Alerts は人間が即座に対応しなくて良いものです。例えば「Datadog Logs でデバッグログが急増した」や「バッチ処理の失敗」などです。Logs の乱暴な増加はコスト増を招くので要対応ですが、だいたいの場合即座に対応ではなく翌朝に対応で問題ありません。バッチ処理もその後の再実行で成功していれば問題ないのでこれに該当したりします。即座に反応して人間の対応が必要なものと、事実としては知りたいがその場で対応する必要がないものを切り分けることでオンコール疲れを減らすことができます。
またチームごとに、#alert-xxx、#notice-xxx という名前で Slack チャンネルを作成した、Actionable に該当するかどうかで分けて運用しています。ちなみにこれらも Team Kit で作成するので新しいチームができ、チーム所属のワークロードがあればこれらのチャンネルも自動で作成されます。人が追加された場合でも勝手にインバイトされるので便利です。
また、Actionable Alerts にもクリティカリティに差があったりします。 同じ CUJ でのアラートでもトップ画面が表示されないのと、一部の商品が表示されないのとでは GMV の損失に差があるからです (あくまで例えです)。こういうケースでは Severity の考えを導入し、アラートにラベリングをしています。こうすることで、SEV-4 アラートは Datadog モニターだけ発火し架電をしない、など柔軟なオンコール制御ができるようになります。
graph TB
A[Alert] --> B[Actionable]
A --> C[Non-Actionable]
B --> D[Slack: alert-xxx]
C --> E[Slack: notice-xxx]
D --> F[SEV-1,2,3]
D --> G[SEV-4]
F --> H[Datadog Monitor 発火]
G --> I[Datadog Monitor 発火]
H --> J[PagerDuty架電]
classDef alert fill:#ffcccc
classDef actionable fill:#ffcccc
classDef nonactionable fill:#ccccff
classDef severity fill:#ffffcc
classDef system fill:#ffccff
class A alert
class B,D,F,G,H,I,J actionable
class C,E nonactionable
class F,G severity
エスカレーションポリシーの整備
Stailer はネットスーパーという性質上、基本お客さまからのリクエストは日中に限られています。しかしデータ連携 (商品データの同期など) などのバッチ処理は、夜間に実行されることも多いです。また問い合わせ対応は土日にも行われるため、エスカレーションポリシーを作成し各チームでオンコール体制を取ってもらっています。どのようなエスカレーションポリシーを敷くかは各チームの責務としています。SRE は Primary、Secondary、Tertiary という3レイヤーのエスカレーションポリシーを提供し、各チームの Team Kit の configuration から enable することで任意のレイヤーを重ねられます。Primary と Secondary はそれぞれの当番に、Tertiary はチーム全員にエスカレーションします。その3レイヤーは、どのようなレイヤーを提供したら 10X の事情を網羅したものが作れるか各開発チームにヒアリングして作ったものです。
例えば、チームの人数が少ないなどの理由で Secondary レイヤを用意できない場合は secondary = false とすることで、Primary が Ack できなかったら全員にコールする (Tertiary)、というような運用が可能です。Primary と Secondary を false にすれば最初から全員にコール (Tertiary) することもできます。
pagerduty = { enable = true members = [ "aaa@10x.co.jp", "bbb@10x.co.jp", "ccc@10x.co.jp", "ddd@10x.co.jp", ] escalation_policy = { primary = true secondary = false tertiary = true } }
graph TB
A[Primary] -->|n分後| B[Secondary]
B -->|m分後| C[Tertiary]
A -.-> D["aaa@10x.co.jp"]
B -.-> E["bbb@10x.co.jp"]
C -.-> F["aaa@10x.co.jp"]
C -.-> G["bbb@10x.co.jp"]
C -.-> H["ccc@10x.co.jp"]
C -.-> I["ddd@10x.co.jp"]
classDef level fill:#ccccff
classDef email fill:#ccffcc
class A,B,C level
class D,E,F,G,H,I email
ちなみに Terraform の Variable Validation を設定することで、{primary = false, secondary = true} のような invalid な入力を弾くことができ便利です。
validation { # pagerduty.enable を true にするなら1つ以上のレイヤーを true にしなければならない condition = !var.pagerduty.enable || var.pagerduty.escalation_policy.primary || var.pagerduty.escalation_policy.secondary || var.pagerduty.escalation_policy.tertiary error_message = "Escalation Policy Layer should be true at least one or more." } validation { # secondary だけ true はありえないパターン condition = !(!var.pagerduty.escalation_policy.primary && var.pagerduty.escalation_policy.secondary && !var.pagerduty.escalation_policy.tertiary) error_message = "Only escalation_policy.secondary cannot be set to true." }
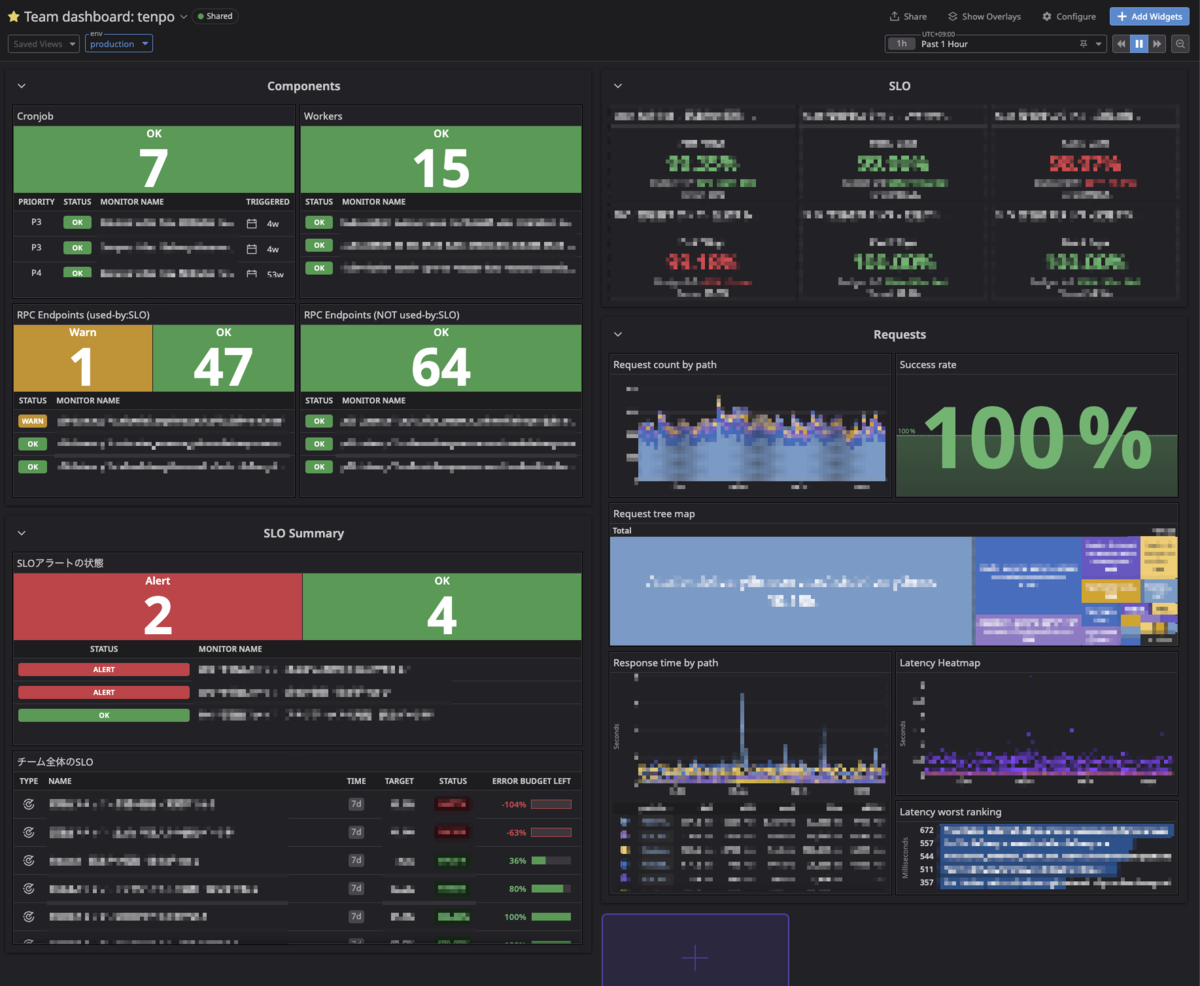
チームダッシュボードの作成
各チームごとにダッシュボードを作成しています。各チームの所有する backend サーバのエンドポイント、CronJob、Worker (batch系のdeployment) を Team Kit の設定ファイルに記述すると以下のようなダッシュボードに自動反映される仕組みになっています。それぞれに Warn/Alert の閾値、またそのエンドポイントが CUJ を構成するか否かを書くことができ、自動で Datadog モニターが作成されます。
owned_cronjob = [ { severity = "SEV-2", name = "generate-xxx" }, { severity = "SEV-3", name = "xxxn-check" }, # ... ] owned_worker = [ { severity = "SEV-3", name = "xxx-worker" }, # ... ] owned_service = { endpoints = [ { path = "/stailer.orderService/createOrder", success_rate = { warning = "99.95%", critical = "99.9%" }, latency = { warning = "100ms", critical = "500ms" }, }, # ... ] user_journeys = [ { name = "注文を作成できる" target = "お客さま" thresholds = [ { timeframe = "30d", critical = 99, warning = 0 }, { timeframe = "7d", critical = 99, warning = 0 }, ] paths = [ "/stailer.orderService/createOrder", # ... ] },
また、毎日チーム全員で見られるようにDatadogダッシュボードをスクショして毎日Slackに送るようにしています。こうすることで管掌役員のような Datadog に普段出入りしていない人間でもサービスの健康状態を見れるようにしています。
SLO
SLO (Service Level Objective、サービスレベル目標) は事業やサービスの提供者が独自に設定する品質目標であり、 昨今では SRE のプラクティスの1つとしてだいぶ普及してきていると思います。また、これを正しく定義し、運用し、SLO を判断基準の1つとしてデプロイ可否などの意思決定の一助としたい会社は多いと思います。まさに 10X も同じく、障害が発生したとき ”Stailer はどれくらいやばいのか (逆に言うとやばくないのか)” を指し示す数値がほしいと思っていました。特に、Stailer は toC だけではなく toB にも責任を追う事業モデルです。SLO の策定は SLA の締結につなげることができます。内部目標を正しく理解をし、運用できるようになることでパートナーへの説明責任につながるとして、全社として SLO の策定に取り組むこととなりました。
CUJ→SLO の策定
一時期 Stailer でよくアラートが発生している時期がありました。SEV によるラベリングもまだで、この障害はどれくらいやばいものなのか、経営メンバーはもちろん担当エンジニア以外やばさの温度感が分かりづらいものもあり、これをなんとかしたいという課題意識がありました。
これはそもそも Stailer が持つ機能を理解して、アプリ利用者に与える機能や体験がどれくらいの価値を持つものなのかを定義できていなかったためです。「売り場が表示されない」「特集バナーが表示されない」「カートに追加できない」はどれもエラーで、同じアラートという扱いになりますが、アプリ上に実装されているすべての機能が Stailer の根幹を支える機能というわけではないはずです。Stailer を語るうえで根幹となるコア体験・コア価値を定め、CUJ (Critical User Journey) を定義することから始まりました。
CUJ や SLO を決定していくために、PdM、SWE、SRE、経営メンバーから構成されるプロジェクトチームを作りました。そしてゴールを SLO の設定、数値の可視化として以下の手順で進めました。
- 過去のインシデントを振り返りどういう傾向があったのかを調べる
- 抱える課題の解決に SLO が役立つと判断する
- SLI/SLO や SLA などの概念を SRE 以外にもインプットする
- Stailer のコア価値をすべて洗い出す
- CUJ (エラーになったらビジネスクリティカルな顧客体験の流れ) を定義する
- その CUJ の利用者 (CUJ User) ごとにグルーピングする (10X の場合、お客さまアプリ、店舗スタッフ向けアプリ、配達スタッフ向けアプリなどがあったため)
- CUJ を構成するエンドポイントを明らかにし、それぞれのエンドポイントごとの SLI を Datadog Monitor にする (SLI はまず Success rate と Latency としました)
- Datadog Monitor のアラート閾値は過去実績から算出しました
- この数値がモニターの赤や緑を判断し、その赤の数が SLO にアグリゲートされるため精緻化は別の課題として設定しました
- CUJ に紐づく Datadog Monitor から構成した Datadog SLOs を作成する
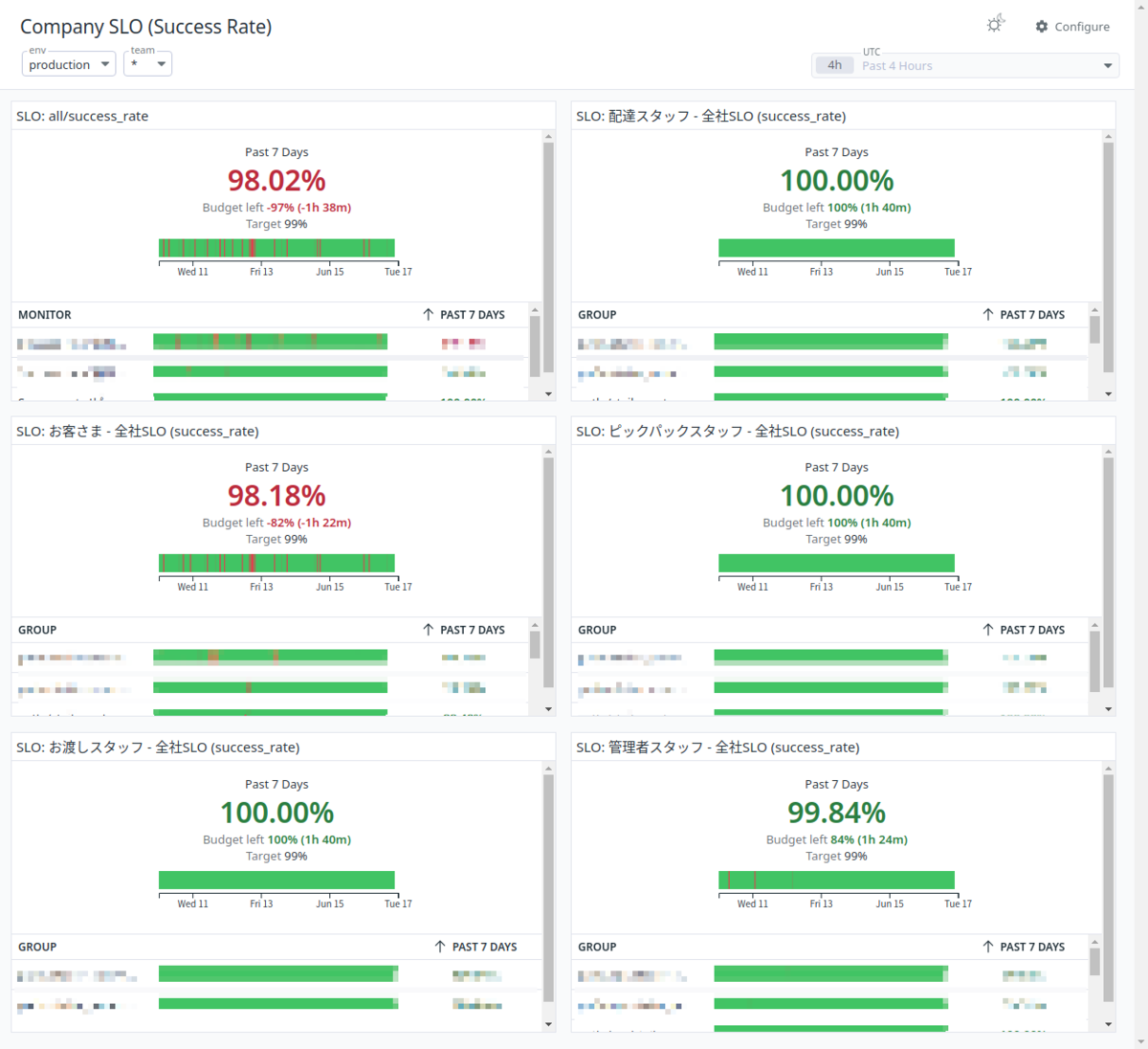
- Datadog SLOs を集めた全社 SLO ダッシュボードを作成する
このような手順で SLO を導入し、全員が Stailer の健康状態を見ることができるようになりました (注釈: 画像の数値はダミーです)。
チームの結成から、CUJ/SLO の策定、全社ダッシュボードをどのように作成したかを過去にまとめて、イベント登壇しているのでそのときのスライドも合わせて参照してみてください。
使われる SLO にしていくまでの営み
SLO を導入するうえで何が一番難しいかというと、自分は「信用され、使われる指標にすること」だと考えています。SLO を決定し、ダッシュボードにまとめ、みんなが見られるようにしたとしても、”見られていない” または ”エンジニアしか見ていない”、”SLO (error budget) が赤だが常にデプロイは止められない” などはよく耳にする話です。見られてなかったり使われていなかったり、見られていても運用が形骸化していては SLO として意味がないので、使われる指標にしていく努力が必要です。
Stailer はパートナー企業向けにアプリを提供しています。つまり、10X はインシデント発生後の説明責任などをパートナーに負うことになる場合がありますが、そういう意味でも SLO が役に立ちます。SLO の設定は SLA 締結にもつながっていくため 10X では特に重視してこれに取り組みました。
- PdM と経営メンバーに SLO/SLA の考え方を理解してもらう
- PdM に SLO の遵守をリードしてもらう (関心を持ってもらう)
- 毎日 SLO ダッシュボードを見れるように各チームの SLO を各チームの Slack チャンネルに通知する
- エラー判定の精緻化 (準正常系などの赤をエラーとしてラベリングしないようにする)
- 決済代行会社の障害など外部サービス連携による SLO の毀損を修正できるようにする
- Stailer として 99% を置いていても外部サービス連携しているサービスの中で一番低い SLA に引っ張られてしまうため SLO Corrections を使って悪影響を回避する
まだまだ改善の余地もありますが、上のような取り組みを経て、今ではなくてはならない指標として活用されています。
コストマネジメント
会社で3年もあればガンガン投資しようぜという攻めフェーズがあったり、逆に財布の紐を締めようフェーズ、または支出を見直してコストカットする守りフェーズもあったりします。Stailer ローンチ以降はいろいろな追い風を受けて新規パートナーセットアップ祭りだったのですが、資金調達のタイミングであったり、いわゆるコロナ特需が落ち着いてきたりと、新規パートナー獲得だけによって利益を追求するのではなく、ネットスーパー事業の黒字化 & Stailer 事業の利益化を追求していこう & ネットスーパー (オンライン) だけではない企業成長の柱を作ろうと方針転換をし、守りのフェーズに入りました。その探索中、SRE として取り組んできた一例をご紹介します。
Google Cloud の代理店契約
これまでは Google Cloud は直接契約でした。つまり支払いが法人カードというだけで一般ユーザの契約と同じようにクレジットカードを登録して月額利用料を支払う形です。しかし Google 公認の販売代理店が行っている Google Cloud 支払代行を活用することで、利用料の数パーセントの割引を受けられるためこれに切り替えました。Google Cloud の代理店は複数ありますが Google が公開している Partner ディレクトリから探すとよいでしょう。複数社で相見積もりを取って比較しより良い条件のところと契約を結びました。
代理店への切り替え作業は意外と簡単で、使用している Billing account を代理店が払い出したものに差し替えるだけです。この Billing account は代理店の Sub Billing Account になっているようでした。
flowchart LR
subgraph "代理店"
A[Billing Account]
B[10X用Sub Billing Account]
end
subgraph "10X Org"
D[Billing Account]
C1[Project]
C2[Project]
C3[Project]
end
A --> B
B --> C1
B --> C2
B --> C3
D -.-> C1
D -.-> C2
D -.-> C3
%% 注釈
D -.- X[差し替え前:<br/>10X Billing → Project]
B -.- Y[差し替え後:<br/>代理店Sub Billing → Project]
Google Cloud の確定利用割引の活用
Google Cloud には確定利用割引 (Committed Use Discount) という割引の仕組みがあります。一定の利用を Google に確約 (コミット) することと引き換えに、通常よりも割引された料金で Google Cloud リソースを利用できるというものです。
- コミットメントは1年間か3年間です
- 前払いではなく、月払いになります。月の利用量から CUD 分のディスカウントが入り月額利用料が決定されます
- コミットメントは Compute Engine や Firestore のように、Google Cloud 内のサービス単位で購入する必要があります
3年の CUD のほうがディスカウントのパーセンテージは高いですが、3年ともなるとさすがにリクエスト動態が読みきれずコミットメントのラインを決められなかったため、1年の CUD を購入しています。CUD による割引は大きく、簡単にコストを削減することができました。
GCE インスタンスの Spot VM への移行
GCE インスタンスの可用性ポリシーに Spot VM というものがあります。標準 VM のオンデマンド価格と比べて、 60~91% という破格の割引を得られる一方で、他のタスクでリソースが必要になった場合などに、Spot VM がプリエンプトされる可能性があるというものです。要するに可用性を落とす代わりに安く使えるよ、というものです。
ワークロードがフォールトトレラントで、VM のプリエンプションが発生する可能性がある場合、Spot VM を使用すると Compute Engine の費用を大幅に削減できます。たとえば、バッチ処理ジョブは Spot VM で実行できます。これらの VM のいくつかが処理中に停止する場合、ジョブは遅くなりますが、完全に停止することはありません。Spot VM は、既存の VM に余分な負荷をかけずにバッチ処理タスクを完了します。標準 VM を追加した場合の正規料金を支払う必要もありません。
10X ではワークロードの約半分が CronJob や Worker です。backend サーバ以上にデータのやり取りが事業上肝となっているためです。そのため多くのバッチ処理ジョブを有するので、Spot VM への移行はかなり効きました。何時までに完了していなければならないといった、SLO を持っているジョブなどを除き基本的には Spot VM に配置しています。また、dev はほぼ全台を Spot VM に移行しています。
SaaS 契約の見直し
以前は CI には CircleCI を使っていました。アプリのビルドや Docker のビルドなど CircleCI 上で行っており、かなりのコストが掛かっていました。GitHub Actions が年々使いやすくなりいまでは GitHub Actions に完全移行し CircleCI は廃止しました。CI 環境を GitHub に寄せることで、GitHub の契約プランと統合でき、ディスカウントなどの恩恵があるので、利用する SaaS をまとめるというのは親和性だけでなくコストにも効いてくると思います。
権限管理
権限付与実態の可視化
SRE チームができた当初から権限管理は大きな課題の1つでした。真っ先に Terraform によるコード化を進めたのも IAM をプルリク経由で付与できるようにしたかったからです。Terraform 導入以前では、そもそも開発メンバーには roles/owner のような強い基本ロールが付与されていました。スタートアップの黎明期ではよくある話だと思います。
これの何が問題かというと、「xx プロジェクトに yy の権限を付与してください」という依頼が多数飛んできてトイルが増えるというのもあげられますが、それ以上に、誰にどんな権限がついたのかレビューできないという点にあります。一時的な付与であったはずのものが付与されっぱなしになっていたり、必要以上の過剰な権限がついてしまったり、別のプロジェクト (リソース) に権限を付けてしまったり、などです。10X ではパートナーごとにプロジェクトを分けているため、意図しないメンバーに意図しないパートナーのリソースやデータが見えるようしてしまうことはインシデントになりうるわけです。
基本的に (ある程度成熟してきた組織での) 手動による IAM 操作は御法度です。roles/owner にはプロジェクトレベルの IAM ポリシーを操作できる権限である resourcemanager.projects.setIamPolicy が含まれます。setIamPolicy があると知らず知らずのうちに権限が無限に増殖していきます。IAM に対する create/update は絶対死守ラインです。プロジェクトを破壊する権限がなくとも IAM を create できたら結局は他の権限に昇格していけるのでセキュリティにおいても、IAM を操作する IAM というのは絶対に守りたいものです。
そのため 10X では以下の手順で権限の整理を始めました。
roles/ownerや admin 系 (storageAdmin など) の強い権限を剥奪する- IAM はすべて Terraform 経由で作成する
- project IAM ではなく、できるだけ resource IAM を使う (bucket IAM member、secret IAM member など)
- 恒常的に必要なロール以外はすべて PAM (Privileged Access Management) にする
今では全ての IAM をコード化したため追加や変更は必ずレビューを通せるようになりました。これでオペミスを減らしたり、過剰な権限を指摘したり、今の IAM 実態がどうなっているかを可視化しやすくなりました。
PAM の導入
権限にはジャストインタイムで必要なものがあったりします。例えば「パートナー A の担当 BIZ がパートナーから GCS 経由で受領したデータを閲覧したい」ケースなどです。常に GCS bucket への viewer を持っておく必要はありませんが、ある一定期間だけ viewer をつけたいケースはよくあります。開発メンバーによる本番操作などもそれに該当するでしょう。
こういうケースにおいて Terraform はあまり向いていません。condition によって有効期限を設定できますが、宣言的すぎるゆえにコードに消し忘れなどが発生するでしょう (消し忘れても Google Cloud 上では IAM は expire し、Terraform State でも無視されるためリポジトリにコードのゴミが残るという以外の実害はありませんが)。
# 権限は condition によって自然消滅するがこのコード自体を消し忘れる resource "google_storage_bucket_iam_member" "aaa_is_storage_object_user_for_partner_sales_report" { bucket = google_storage_bucket.partner_sales_report.name role = "roles/storage.objectUser" member = "user:aaa@10x.co.jp" # 一時的に付与した権限 condition { title = "expires_after_2025_06_30" description = "2025-06-30まで一時的に付与" expression = "request.time < timestamp(\"2025-06-30T00:00:00Z\")" } }
こういったケースでは PAM (Privileged Access Manager) を使うと良い感じに解決できます。PAM では利用資格を定義し、その資格に基づいて権限の付与が行われます。
利用資格には次のような設定が必要です:
- 申請可能な人 (その人に対して付与する)
- Approve (Deny) 可能な人
- 対象リソース (Organization、フォルダ、プロジェクト、リソース。リソースの場合は condition によるリソース指定が必要)
- 付与するロール (
roles/editorなどの基本ロールOK、複数OK、カスタムロールOK) - 有効期限
具体的な例を上げるなら、次のような利用資格をイメージするとわかりやすいです:
- 申請可能:
all_bizdev@10x.co.jpに所属する BIZ メンバー - 承認可能: SRE, Security
- 対象リソース: XX プロジェクトの YY バケット
- ロール:
roles/storage.objectViewerroles/storage.objectCreator
- 有効期限: 12時間
このように PAM はただの利用資格の定義です。申請が Approve されるとこの利用資格の情報をもとにして IAM が作成されます。その IAM には自動的に IAM condition として有効期限が設定されるため、期間が終了すると、Privileged Access Manager によってロールが取り消してくれるという仕組みでジャストインタイムな IAM 作成が可能です。これで Terraform で一時的な権限を管理する必要がなく、ノーコードで宣言的に権限付与が行えます。また、PAM の利用は監査ログに残ります。Terraform で担保していた PR で証跡を残すという点は監査ログで代替できると思います。
このように PAM はかなり便利な機能でありますが、比較的新しい機能であるため、まだイマイチの点もあったりします。
一つは付与対象がリソースの場合、指定にクセがあります。secret IAM member のように特定の Secret Manager の Secret Version だけを読めるようにしたいなどのケースです。リソース指定は CEL で記述し IAM condition になるため CEL 記法にミスがあった場合 condition が false になり権限が付与されません。これは文法エラーなのか、condition の false なのか簡単にはわからないためサイレントに ”付与されない” という現象が発生します。
もう一つは付与の代理ができないという点です。付与するプリンシパルと申請する人は同一でなければなりません。例えば all_bizdev@10x.co.jp という Google Group があったときに、申請する人はそのグループに入っていないといけないのです。BIZ の人の代行を SWE がやる、などはできないようになっています。
とはいえ、PAM はかなり便利で基本的に「常に必要」な権限以外はどんどん PAM に移していっています。おそらくサービスアカウントのような機械的に使われるプリンシパル以外、つまり人間 (user, group, domain) に対する権限のほとんどは PAM にできるのではないかと思っています。
Deny Policy の整備
Google Cloud には Deny Policy という IAM ロールの制御方法があります。ちなみにこれまでのリソースへのアクセスを許可する IAM は Allow Policy です。Deny Policy はその逆に作用するリソースで、任意の Google Cloud リソースへのアクセスを拒否することができます。
Google Cloud リソースへのアクセスにガードレールを設定できます。拒否ポリシーを使用すると、付与されるロールに関係なく、特定のプリンシパルが特定の権限を使用できないようにする拒否ルールを定義できます。 拒否ポリシー | IAM Documentation | Google Cloud
つまり、いかなる IAM が付与されていたとしてもそれを無視して任意の操作を拒否することができます。また、この Deny Policy は Allow Policy の IAM と同様にリソース階層に従って継承されます。
Deny Policy が一番有効に働くのは Delete 系の拒否でしょう。多くの会社でもそうだと思いますが、10X の場合だと Firestore や Cloud SQL あたりのデータベース自体の Delete は実行する機会がありません。そのため Deny で実行自体できないようにしておいたほうが安全です。Google Cloud Project の Delete も拒否しています。パートナーのチャーンなどで Project 自体使用しなくなるケースはあるのですが、Google Cloud の場合 Project ID の再取得はかなり難しいため Soft Delete 扱いにして実際には消さないようにしておいたほうが好都合なためです。
以下は Terraform で記述した場合の例です。
resource "google_iam_deny_policy" "all_principals_delete_operation" { provider = google-beta parent = urlencode("cloudresourcemanager.googleapis.com/organizations/${var.org_id}") name = "all-principals-delete-operation" rules { deny_rule { denied_principals = ["principalSet://goog/public:all"] denied_permissions = ["cloudresourcemanager.googleapis.com/projects.delete"] exception_principals = [ # NOTE: 例外プリンシパルを設定する場合は以下のようにPrincipalを指定する # https://cloud.google.com/iam/docs/principal-identifiers#v2 "principal://iam.googleapis.com/projects/-/serviceAccounts/<name>@<project-id>.iam.gserviceaccount.com", // service account # "principalSet://goog/group/<group_name>@10x.co.jp", // group # "principal://goog/subject/<user_name>@10x.co.jp", // user ] } } }
Allow Policy は Terraform や PAM によってレビューを通しているわけだし、恒常的な強い権限を与えていないのであれば Deny Policy までは不要では?と思われるかもしれません。しかし、Google Cloud の場合、何故か (本当に何故か) たまに何かの連携時に Admin 系のロールを求められるケースがあります。特に Firestore 周りの設定です。Firestore の Analytics を有効にし BigQuery との連携を有効化するためにはプロジェクト管理者 (roles/owner) や Firebase 管理者 (roles/firebase.admin) が必要、などが挙げられます。これらもその設定のときだけ roles/owner を付与する PAM を設定しているのですが (前述したように roles/owner には setIamPolicy が含まれるため本当は付与したくない...)、一時的にでも roles/owner を持ってしまうと project delete が可能な状態になってしまいます (roles/firebase.admin も同様で firebase.projects.delete が含まれます)。危険な操作が実行可能な状態である以上、どんなミスも可能性としては起こり得るので、万が一のためにも Deny Policy があったほうがやはり安心です。また、本当に一部ですが Org Admin のような強い権限を持つ管理者もいます。Terraform 実行用のサービスアカウントなどもそれに該当します。うっかり消えてしまった、がないようにやはり API レベルで拒否されるという、最後の砦的な意味でのガードレールがあると安心です。
また、最強権限である Organization Administrator (roles/resourcemanager.organizationAdmin) であっても Deny Policy が優先されるため、例えば Org Admin が Project Delete などを実行しても拒否されます。これによりオペミスを防ぐ強固な手段として利用できる一方で、Deny Policy はセキュリティ向上のツールとしては使えません。Org Admin のロール自体は Deny Policy を作成・削除する iam.denypolicies.* を持ちませんが setIamPolicy ができるため自分で Deny Admin (roles/iam.denyAdmin) に昇格し、任意の Deny Policy を削除できるためです (検証済み)。そのため、Deny Policy はあくまでもオペミスを防ぐ安全装置として活用するのが望ましいです。
最後に
このブログ記事では、これまでの SRE が取り組んできたものの中で粒だったものをいくつかピックアップしてご紹介しました。10X ではこれから新規事業のローンチや複数の新規パートナーのローンチなど、かなりの大目玉が控えています。今の 10X、かなり楽しいです。今のこの成長を支えてくれる SRE を募集しています!JD も公開したので合わせて参照していただけると嬉しいです。
*1:Organization