データエンジニア業務委託のjcです。 今回は、GKEでArgo WorkflowsにWorkflow Archiveを導入する話を共有します。 Argo Workflowを利用している方・利用検討中の方のご参考になればと思います。
Argo Workflowsとは
Argo Workflowsは、Kubernetes上でJobを実行するためのワークフローエンジンです。 Kubernetesネイティブであるため、リソースの管理やスケールが容易であり、Airflowなどの他のワークフローエンジンとは異なり、別途計算リソースを用意したり、schedulerを設定したりする必要がありません。 ただし、Kubernetesクラスタの管理コストが発生するため、Argo Workflowsが最強のワークフローエンジンであるとは一概には言えません。
Workflow Archiveを使う理由
Kubernetesでは、実行済みのPodを回収するGarbage Collectionメカニズムが実装されています。
過去の実行履歴も確認できるようにするために、Argo WorkflowsではGarbage Collectionを一時的に回避する機能が実装されており、controllerの環境変数 ARCHIVED_WORKFLOW_GC_PERIODで保持期間を設定できます。また、パラメータTTLStrategyを設定することでWorkflowの生存期間を個別に設定することもできます。
一方で、Pod自体のコストやPodを監視するコストなどがかかるため、長期間保存に向いてません。 Workflow ArchiveはArgo Workflowsが提供している機能で、実行済みのワークフローをデータベースに保存することで、UIから過去のworkflow実行履歴一覧を確認できます。
Workflow Archiveの導入方法
Workflow Archive機能を軽く動作確認してイメージを掴みたい場合、公式のquick-start-postgres.yamlをそのままapplyするとPostgreのPodと設定済みのConfigMapがArgo Workflows本体と一緒に作成されるため、最もシンプルだと思います。
The quick-start deployment includes a Postgres database server. In this case the workflow archive is already enabled. Such a deployment is convenient for test environments, but in a production environment you must use a production quality database service.
Note that IAM-based authentication is not currently supported
Workflow Archive - Argo Workflows - The workflow engine for Kubernetes
ただし、ドキュメントに記載しているように、ステートレスなPodは本番環境に向いておらず、IAMベースの認証にも対応していないため、本番環境ではマネージドデータベースを利用するのが一般的です。 Argo Workflows用KubernetesクラスタがGCPにデプロイされている場合、Cloud SQLを利用すると便利です。しかし、Cloud SQL Auth ProxyとPrivate IPの設定などを含めて、考慮すべき事項が増えます。実際に適用する際に苦労したため、その詳細をこのエントリで紹介します。
続いて、Terraformのリソース作成例とKubernetesのマニフェスト例を挙げながら、詳細なステップを紹介していきます。
Cloud SQLの設定
まずはCloud SQLを作成します。
ワークフローの数と保持期間にもよりますが、この例では最も小さいインスタンスdb-f1-micro利用しています。
本記事はWorkflow Archiveの設定に着目しているため、google_service_networking_connectionを含めてネットワーク周りの設定は割愛します。
data "google_compute_network" "default" { name = "default" project = "YOUR-PROJECT-ID" } resource "google_sql_database_instance" "workflow_archive" { project = "YOUR-PROJECT-ID" name = "workflow-archive" region = "asia-northeast1" database_version = "POSTGRES_15" depends_on = [google_service_networking_connection.cloudsql_workflow_archive_vpc_connection] settings { tier = "db-f1-micro" ip_configuration { ipv4_enabled = false private_network = data.google_compute_network.default.id enable_private_path_for_google_cloud_services = true } backup_configuration { enabled = true point_in_time_recovery_enabled = true } availability_type = "REGIONAL" } }
サービスアカウントの設定
Cloud SQLにアクセスするために、GCP側のサービスアカウント(GSA)とKubernetes側のサービスアカウント(KSA)両方の設定が必要です。
公式のHelm Chartでインストールする場合、server用のKSA argo-workflows-serverとcontroller用のKSA argo-workflows-workflow-controllerが最初から作成されているため、追加でGSAを作成し、CloudSQLへの読み取り権限を付与します。
resource "google_service_account" "workflow_server" { project = "YOUR-PROJECT-ID" account_id = "workflow-server" display_name = "workflow-server" }
resource "google_project_iam_member" "workflow_server_is_cloudsql_client" { project = "YOUR-PROJECT-ID" role = "roles/cloudsql.client" member = "serviceAccount:${google_service_account.workflow_server.email}" }
GSAをKSAに紐付けます。
resource "google_service_account_iam_member" "ksa_workflow_server_becomes_gsa_workflow_server" { service_account_id = google_service_account.workflow_server.name role = "roles/iam.workloadIdentityUser" member = "serviceAccount:YOUR-PROJECT-ID.svc.id.goog[workflows/argo-workflows-server]" depends_on = [ google_service_account.workflow_server ] }
さらに、KSAにGSAのアノテーションを追加して、サービスアカウントの設定が完了します。
apiVersion: v1 kind: ServiceAccount metadata: name: argo-workflows-server annotations: iam.gke.io/gcp-service-account: workflow-server@your-project.iam.gserviceaccount.com
controllerのサービスアカウントの設定はserverと全く同じなので、ここでは省略します。
Cloud SQL Auth Proxyとアクセス情報の設定
サービスアカウントの設定をした後、Cloud SQL Auth Proxyとアクセス情報の設定を行います。 Cloud SQL Auth Proxyを利用すると、静的なIPアドレスを提供する必要がなく、GKEクラスタから直接Cloud SQLのインスタンスに接続できます。 最小権限の原則に従い、Cloud SQLへのアクセス権限はクラスタ全体ではなく、アプリケーションArgo Workflowsのみに付与します。 そのため、SidecarパターンでCloud SQL Auth Proxyを設定します。
controllerとserverのDepolymentに以下sidecarを入れます。(Kustomizationなど利用してpatchを当てる方法が一般的です)
name: cloud-sql-proxy image: gcr.io/cloud-sql-connectors/cloud-sql-proxy:2.11.0 args: - "--private-ip" - "--structured-logs" - "--port=5432" - "YOUR-PROJECT-ID:asia-northeast1:workflow-archive" securityContext: runAsNonRoot: true resources: requests: cpu: "1" memory: "2Gi"
最終的にserverのDeploymentは以下のようになります。
apiVersion: apps/v1 kind: Deployment metadata: labels: app.kubernetes.io/component: server app.kubernetes.io/instance: argo-workflows app.kubernetes.io/managed-by: Helm app.kubernetes.io/name: argo-workflows-server app.kubernetes.io/part-of: argo-workflows app.kubernetes.io/version: v3.5.7 helm.sh/chart: argo-workflows-0.41.7 name: argo-workflows-server namespace: workflows spec: replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: app.kubernetes.io/instance: argo-workflows app.kubernetes.io/name: argo-workflows-server template: metadata: labels: app.kubernetes.io/component: server app.kubernetes.io/instance: argo-workflows app.kubernetes.io/managed-by: Helm app.kubernetes.io/name: argo-workflows-server app.kubernetes.io/part-of: argo-workflows app.kubernetes.io/version: v3.5.7 helm.sh/chart: argo-workflows-0.41.7 spec: containers: - args: - server - --configmap=argo-workflows-workflow-controller-configmap - --namespace=workflows - --auth-mode=server - --secure=false - --loglevel - info - --gloglevel - "0" - --log-format - json env: - name: IN_CLUSTER value: "true" - name: ARGO_NAMESPACE valueFrom: fieldRef: apiVersion: v1 fieldPath: metadata.namespace - name: BASE_HREF value: / image: quay.io/argoproj/argocli:v3.5.7 imagePullPolicy: Always name: argo-server ports: - containerPort: 2746 name: web readinessProbe: httpGet: path: / port: 2746 scheme: HTTP initialDelaySeconds: 10 periodSeconds: 20 resources: {} securityContext: allowPrivilegeEscalation: false capabilities: drop: - ALL readOnlyRootFilesystem: false runAsNonRoot: true volumeMounts: - mountPath: /tmp name: tmp - args: - --private-ip - --structured-logs - --port=5432 - YOUR-PROJECT-ID:asia-northeast1:workflow-archive image: gcr.io/cloud-sql-connectors/cloud-sql-proxy:2.11.0 name: cloud-sql-proxy resources: requests: cpu: "1" memory: 2Gi securityContext: runAsNonRoot: true nodeSelector: kubernetes.io/os: linux serviceAccountName: argo-workflows-server volumes: - emptyDir: {} name: tmp
DeploymentにSidecarを追加した後、ConfigMapにWorkflow Archiveの関連設定を追加します。
同じPod内にあるproxyのsidecarにアクセスすれば良いので、host、portおよびdatabaseはデフォルト値で問題ありません。
DBにアクセスするためのusernameとpasswordはセンシティブな情報のため、Secret Managerに入れてExternal Secretを利用して取得した方が良いでしょう。詳細は割愛します。
persistence: connectionPool: maxIdleConns: 100 maxOpenConns: 0 connMaxLifetime: 0s nodeStatusOffLoad: true archive: true archiveTTL: 7d postgresql: host: localhost port: 5432 database: postgres tableName: argo_workflows userNameSecret: name: workflow-archive-db-username key: username passwordSecret: name: workflow-archive-db-password key: password
動作確認
最後に動作確認を行います。
Argo WorkflowsのUIにアクセスすると、実行済みのworkflowのARCHIVEDカラムがtrueになり、Pod自体が消えてもWorkflowが表示され続けます。
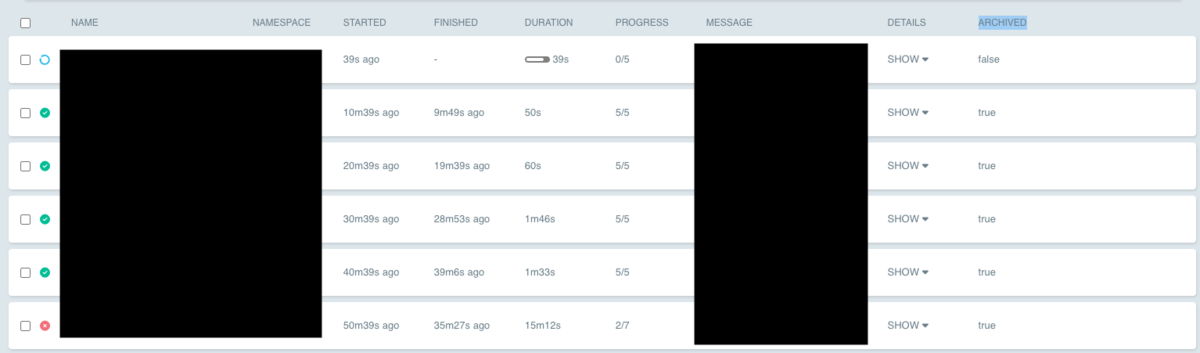
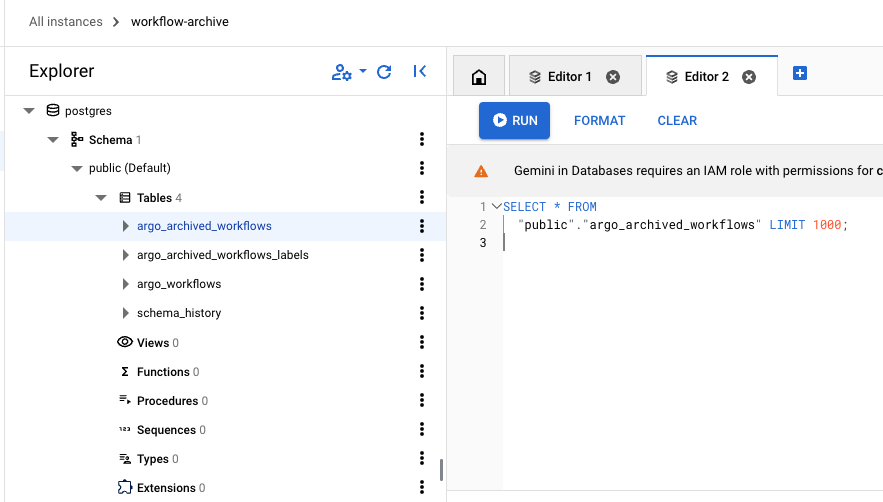
DBからも実行済みのWorkflow情報を確認できます。
まとめ
本記事では、GKEでArgo WorkflowsにWorkflow Archiveを導入する理由と方法について紹介しました。 ご参考になれば幸いです。